BigQuery DataFrames를 통해 Gemini로 텍스트 데이터를 보강하는 방법

데이터 증대(Data Augmentation)는 기존 데이터에서 새로운 데이터를 생성하여 데이터 세트의 크기를 늘리기 위해 기계 학습에서 사용되는 기술입니다. 이 기술은 모델이 훈련된 데이터에 대한 과적합을 방지하여 더 효과적으로 일반화하는 데 도움이 될 수 있습니다.
데이터 회전, 뒤집기, 자르기 등을 통해 시각적 데이터에서 이 작업을 수행하는 것을 종종 생각합니다. PyTorch에는 단 몇 줄의 코드만으로 데이터 세트에 무작위 변환을 적용할 수 있는 매우 유용한 변환 패키지가 있습니다. 이로 인해 훈련 세트의 정확도가 감소할 수 있지만, 보이지 않는 데이터의 테스트 세트에 대한 정확도가 향상되는 경우가 많습니다. 이것이 바로 정말 중요합니다!

예: 암석 이미지의 데이터 확대 출처: TseKiChun, CC BY-SA 4.0, Wikimedia Commons 경유
이 동일한 기술을 텍스트 데이터에 적용할 수 있습니다. 이는 기존 데이터 세트를 확장하고 모델을 노이즈 및 이상값에 더욱 강력하게 만드는 것과 동일한 이점을 제공합니다. 모든 데이터 세트의 데이터 확대에는 입증된 이점이 있으며, 이는 특히 소규모 데이터 세트에 유용합니다.
널리 사용되는 기술을 사용하여 몇 가지 예를 살펴보겠습니다.
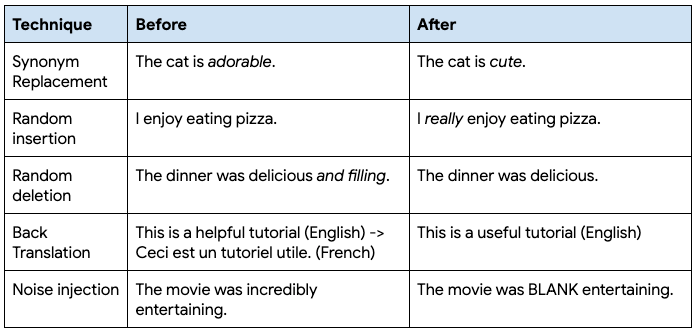
이러한 기술을 수동으로 적용할 수 있는 방법에는 여러 가지가 있습니다.삭제된 토큰의p=0.1인 무작위 삭제 기술을 적용한다고 가정해 보겠습니다.텍스트를 토큰화한 다음(1-p)확률로 토큰을 다시 추가할 수 있습니다. 또는 역번역의 경우 대상 언어에 대해Translation API를한 번 호출한 다음 다시 원래 언어로 번역하기 위해 두 번째 호출할 수 있습니다. 동의어의 경우임의 토큰에WordNet API를사용할 수 있습니다.
Gemini와 같은 강력한 LLM을 사용하면손끝에서 많은 트릭을 얻을 수 있습니다. 하나의 도구 세트에서 이러한 수정 작업을 비롯한 다양한 작업을 쉽게 수행할 수 있습니다. 더 이상 여러 도구를 엮을 필요가 없습니다.
스택 오버플로 질문과 답변으로 구성된 실제 데이터 세트에 이러한 기술을 적용하는 방법을 살펴보겠습니다. 모든 세부 사항은 이노트에 제공되어 있으며 여기서 주요 내용을 지적하겠습니다.
모든 종류의 문제에 BigQuery DataFrame을사용할 수 있지만BigQuery 데이터 세트의 텍스트 확대가 특히 간단해집니다. 이는 Gemini를 직접 쿼리할 수 있는 pandas 호환 DataFrame 및 scikit-learn과 유사한 ML API를 제공합니다. 모든 DataFrame 저장소가 BigQuery에 있으므로 대규모 데이터세트에 대한 일괄 작업을 처리할 수 있습니다.
이제 이러한 기술 중 하나인 동의어 교체를 시작해 보겠습니다. 먼저, 2020년부터 허용된 Stack Overflow Python 답변을 쿼리하고 이를 BigQuery DataFrame에 넣을 수 있습니다.
stack_overflow_df = bpd.read_gbq_query(
"""SELECT
CONCAT(q.title, q.body) AS input_text,
a.body AS output_text
FROM `bigquery-public-data.stackoverflow.posts_questions` q
JOIN `bigquery-public-data.stackoverflow.posts_answers` a
ON q.accepted_answer_id = a.id
WHERE q.accepted_answer_id IS NOT NULL
AND REGEXP_CONTAINS(q.tags, "python")
AND a.creation_date >= "2020-01-01"
LIMIT 550
""")
다음은 Q&A DataFrame을 살짝 엿본 것입니다.

이제 데이터프레임에서 여러 행을 무작위로 샘플링해 보겠습니다. n_rows를 원하는 새 샘플 수로 설정합니다.
df = stack_overflow_df.sample(n_rows)
그런 다음 Gemini 텍스트 생성기 모델을 정의할 수 있습니다.
model = GeminiTextGenerator()
다음으로 입력 텍스트와 연결된 동의어 대체 지침이 포함된 프롬프트 열과 동의어 대체가 적용된 결과 열이라는 두 개의 열을 생성해 보겠습니다.
# Create a prompt with the synonym replacement instructions and the input text
df["synonym_prompt"] = (
f"Replace {n_replacement_words} words from the input text with synonyms, "
+ "keeping the overall meaning as close to the original text as possible."
+ "Only provide the synonymized text, with no additional explanation."
+ "Preserve the original formatting.\n\nInput text: "
+ df["input_text"])
# Run batch job and assign to a new column
df["input_text_with_synonyms"] = model.predict(
df["synonym_prompt"]
).ml_generate_text_llm_result
# Compare the original and new columns
df.peek()[["input_text", "input_text_with_synonyms"]]
결과는 다음과 같습니다! 동의어 대체를 통해 텍스트의 미묘한 변화를 확인하세요.

이 프레임워크를 사용하면 모든 종류의 일괄 변환을 적용하여 데이터를 늘리는 것이 간단합니다. 노트북에는 역번역 및 노이즈 주입에 사용할 수 있는 더 많은 프롬프트가 표시됩니다. 또한 BigQuery DataFrames를사용하여 데이터 세트를 향상하는 것이 얼마나 쉬운지 확인했습니다.