How to Train and Optimize A Neural Network

배경
deep learning을 할 줄 아냐고 항상 부담이 된다. 이름부터 어려워 보이는 deep learning 에 대해 pytorch 라이브러리를 활용해 간단히 사용 방법을 알아보자.
Deep Learning
딥러닝은 머신 러닝의 하위 집합으로, 특히 사람의 뇌 구조와 기능에서 영감을 얻은, 알고리즘을 포함한 대량의 데이터를 다룹니다. 그래서 딥러닝 모델을 종종 심층 신경망이라고 부르는 것입니다.
Dataset
복잡하고 수 많은 작업이 필요한 데이터 전처리 과정들은 제외하기 위해 small iris dataset 활용.
Load Data with Data Loader
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDataset
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
from IPython import display
display.set_matplotlib_formats("svg")
iris = pd.read_csv("https://gist.githubusercontent.com/netj/8836201/raw/6f9306ad21398ea43cba4f7d537619d0e07d5ae3/iris.csv")
iris.head()
head() 메서드를 활용해 dataset의 컬럼과 실제값을 간단히 확인합니다.
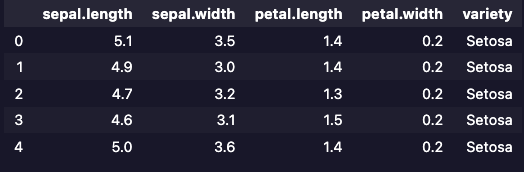
딥러닝을 통해 예측할 목표는 variety 컬럼이다. 다른 4개의 컬럼에 따라 이 컬럼의 값이 변경된다고 보면 됩니다. 수식으로 생각하면 4개의 컬럼을 X, 목표로 하는 예측값을 y로 해서 생각해 봅니다.
X = torch.tensor(iris.drop("variety", axis=1).values, dtype=torch.float)
y = torch.tensor(
[0 if vty == "Setosa" else 1 if vty == "Versicolor" else 2 for vty in iris["variety"]],
dtype=torch.long
)
print(X.shape, y.shape)
위의 코드와 같이 불러온 데이터에서 variety 컬럼을 제거한 것을 X, variety 만 불러온 것을 y로 합니다. 이 때 variety 컬럼의 값들 중 Setosa를 0, Versicolor를 1, 나머지를 2로 변환해 줍니다.
Train / Test split
이제 training할 데이터들과 실제 이를 검증할 test 데이터들을 나누어 줍니다.
미리 import 해 둔 from sklearn.model_selection import train_test_split 라이브러리를 사용하면 됩니다.
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=42)
train_data = TensorDataset(X_train, y_train)
test_data = TensorDataset(X_test, y_test)
train_loader = DataLoader(train_data, shuffle=True, batch_size=12)
test_loader = DataLoader(test_data, batch_size=len(test_data.tensors[0]))
print("Training data batches:")
for X, y in train_loader:
print(X.shape, y.shape)
print("\nTest data batches:")
for X, y in test_loader:
print(X.shape, y.shape)
Training
딥러닝을 위해 만들 모델은 input layer과 output layer를 연결하는 16개의 노드와 단일 hidden layer를 활용합니다.
class Net(nn.Module):
def __init__(self):
super().__init__()
self.input = nn.Linear(in_features=4, out_features=16)
self.hidden_1 = nn.Linear(in_features=16, out_features=16)
self.output = nn.Linear(in_features=16, out_features=3)
def forward(self, x):
x = F.relu(self.input(x))
x = F.relu(self.hidden_1(x))
return self.output(x)
model = Net()
print(model)
모델을 만들었으니 이제 training을 시작하는데 반복 동작하면서 오차를 줄여가는 과정을 수행하게 됩니다.
Crossentropyloss를 사용해 오차를 추적하고 Adam으로 경사 하강 과정을 진행합니다.
num_epochs = 200
train_accuracies, test_accuracies = [], []
loss_function = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.01)
for epoch in range(num_epochs):
# Train set
for X, y in train_loader:
preds = model(X)
pred_labels = torch.argmax(preds, axis=1)
loss = loss_function(preds, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_accuracies.append(
100 * torch.mean((pred_labels == y).float()).item()
)
# Test set
X, y = next(iter(test_loader))
pred_labels = torch.argmax(model(X), axis=1)
test_accuracies.append(
100 * torch.mean((pred_labels == y).float()).item()
)
데이터가 작아 금방 완료되는데요. 반복 동작의 횟수 당 정확도가 어떻게 나왔었는지 시각화를 통해 보게 되면 아래와 같습니다.
fig = plt.figure(tight_layout=True)
gs = gridspec.GridSpec(nrows=2, ncols=1)
ax = fig.add_subplot(gs[0, 0])
ax.plot(train_accuracies)
ax.set_xlabel("Epoch")
ax.set_ylabel("Training accuracy")
ax = fig.add_subplot(gs[1, 0])
ax.plot(test_accuracies)
ax.set_xlabel("Epoch")
ax.set_ylabel("Test accuracy")
fig.align_labels()
plt.show()
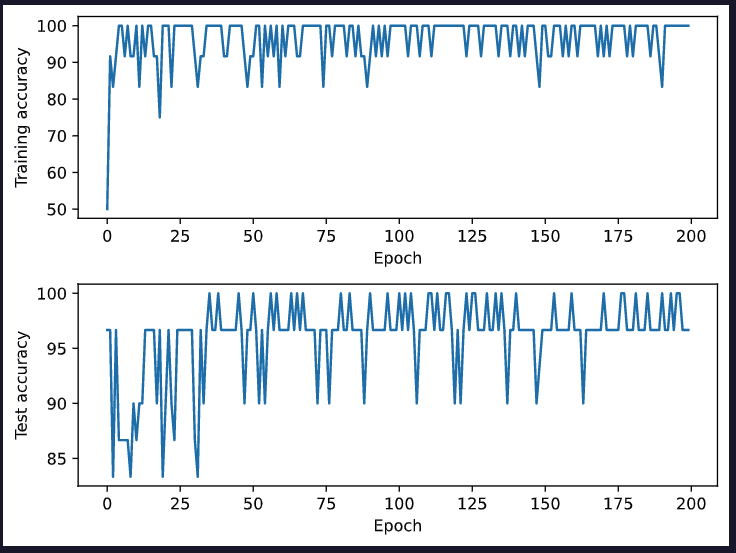
Optimization
- 우선 트레이닝 과정을 아래와 같이 단순화합니다.
losses = []
def train_model(train_loader, test_loader, model, lr=0.01, num_epochs=200):
train_accuracies, test_accuracies = [], []
loss_function = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model.parameters(), lr=lr)
for epoch in range(num_epochs):
for X, y in train_loader:
preds = model(X)
pred_labels = torch.argmax(preds, axis=1)
loss = loss_function(preds, y)
losses.append(loss.detach().numpy())
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_accuracies.append(
100 * torch.mean((pred_labels == y).float()).item()
)
X, y = next(iter(test_loader))
pred_labels = torch.argmax(model(X), axis=1)
test_accuracies.append(
100 * torch.mean((pred_labels == y).float()).item()
)
return train_accuracies[-1], test_accuracies[-1]
train_model(train_loader, test_loader, Net())
- layer 개수를 조절할 수 있는 새로운 모델 클래스를 생성합니다.
class Net2(nn.Module):
def __init__(self, n_units, n_layers):
super().__init__()
self.n_layers = n_layers
self.layers = nn.ModuleDict()
self.layers["input"] = nn.Linear(in_features=4, out_features=n_units)
for i in range(self.n_layers):
self.layers[f"hidden_{i}"] = nn.Linear(in_features=n_units, out_features=n_units)
self.layers["output"] = nn.Linear(in_features=n_units, out_features=3)
def forward(self, x):
x = self.layers["input"](x)
for i in range(self.n_layers):
x = F.relu(self.layers[f"hidden_{i}"](x))
return self.layers["output"](x)
- layer를 1~4개까지 증가시켜 보고 각 layer가 8, 16, 24, 32, 40, 48, 56개 노드를 각각 가졌을 때 어떻게 변화하는지 지켜봅니다.
n_layers = np.arange(1, 5)
n_units = np.arange(8, 65, 8)
train_accuracies, test_accuracies = [], []
for i in range(len(n_units)):
for j in range(len(n_layers)):
model = Net2(n_units=n_units[i], n_layers=n_layers[j])
train_acc, test_acc = train_model(train_loader, test_loader, model)
train_accuracies.append({
"n_layers": n_layers[j],
"n_units": n_units[i],
"accuracy": train_acc
})
test_accuracies.append({
"n_layers": n_layers[j],
"n_units": n_units[i],
"accuracy": test_acc
})
train_accuracies = pd.DataFrame(train_accuracies).sort_values(by=["n_layers", "n_units"]).reset_index(drop=True)
test_accuracies = pd.DataFrame(test_accuracies).sort_values(by=["n_layers", "n_units"]).reset_index(drop=True)
test_accuracies.head()
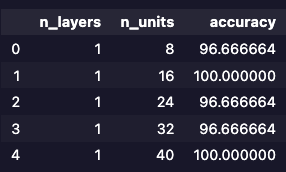
결과를 보면 테스트 정확도는 layer가 몇 개일 때 node가 몇 개일 때 어떤 양상을 보였는지 알 수 있고 test_accuracies[test_accuracies["accuracy"] == test_accuracies["accuracy"].max()] 를 통해 이 중 가장 정확도가 높은 layer, node 개수를 선정할 수 있습니다.
결론
iris dataset은 굉장히 적은 데이터이고 training이 굉장히 잘 되는 데이터이기에 이 과정이 무의미해 보이도록 정확도가 대부분이 정확도가 높게 나왔습니다.
하지만 실제 업무에서는 이처럼 깨끗하지 않고 깨끗하더라도 경향성이 일관되지 않아 그 수식을 찾아내기 힘든 경우가 대다수기 때문에 이와 같은 과정들이 필요합니다. layer, node 개수를 조정해 보는 것 외에도 변수들을 조절해 모델에 변화를 주거나 training 방식의 변화를 주어 optimization을 한다면 보다 의미있는 값들을 도출할 수 있을 거라 생각합니다.
이 글을 쓰면서 딥러닝에 좀 더 자신감을 가질 수 있으면 좋겠다 나도..;