사용해 본 MCP 중 추천
· One min read
준비중입니다
준비중입니다

최근 회사에서 워크샵을 진행하는데, AI 관련 발표를 하게 됐는데, ppt를 만든 경험이 적어 어떻게 하지 고민하다가 웹사이트를 만들어 바로 보고 언제든 자료를 볼 수 있도록 개발을 시작 했습니다.
우선 다른 분들의 ppt 양식과 같이 ppt를 먼저 만들고, 그 형식에 맞게 웹사이트를 만들자가 전체적인 그림이었습니다. (이렇게 하면 웹사이트도 ppt도 둘 다 있어 리스크가 없으니...)
개발자들이 좋아하는 markdown 파일에 요구사항을 적고, claude에 이 내용을 ppt에 쓰도록 자세히 만들어 달라고 여러 차례 prompt 작업을 하니 내용이 찼습니다.
그리고 windsurf에서 marp 확장 프로그램을 설치했습니다.(pdf, ppt를 md를 통해 만들어주는 확장 프로그램)
그런 뒤 windsurf에서 marp 확장 프로그램을 통해 ppt로 추출할 계획이니 내용을 포맷에 맞춰서 만들어 달라고 요청하자!

미리보기까지 보니 오 제대로네!
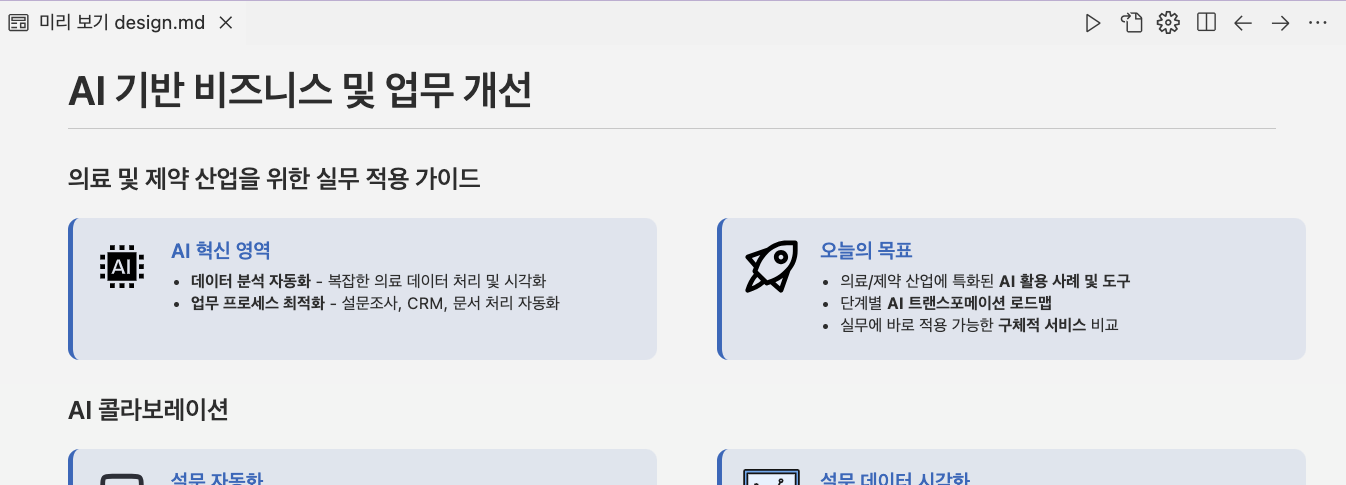
그런 뒤 cascade에 초기 요구사항과 ppt용 md 파일을 참조해 웹사이트를 개발해 달라고 prompt 하니 빠르게 웹사이트를 개발해 냅니다. 🚀
이제 남은 건 추후 수정에 용이하도록 기존 요청한 공통 모듈, 테마 등이 잘 적용되지 않은 부분을 체크하고 수정하여 개발 완료!
AI를 활용한 개발은 오래 됐지만, 최근에는 실수가 잦지만 엄청 많이 알고 있는 개발자 분과 함께 개발하는 느낌이다.
이제 검토와 유지 보수를 위해 클린 코드를 작성하도록 prompt로 유도하는 것이 점점 중요해지는 것 같다.
Vscode를 쓰다가 Windsurf 없이 이제 코딩이 힘들어졌다.
AI 사용을 위해 지속적으로 업데이트 중인 앱을 따라갈 수는 없는 것 같다.
Windsurf를 추천합니다.
Pre-trained AI를 활용해서 Serverless로 Image에서 Text를 추출해 번역하는 앱을 Google Cloud에서 구축하려고 해봤다.
Cloud Run으로 클라이언트 앱을 호스팅하고 Cloud Functions로 백엔드 로직을 실행시키며, Google의 pre-trained된 AI를 사용할 수 있는 API를 활용합니다.
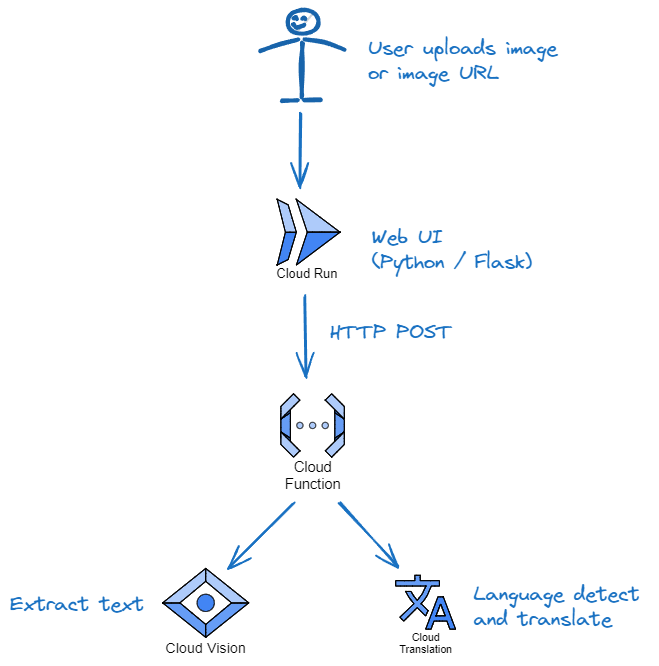
1. 사용자 입력을 수집하고 이미치를 캡처해 백엔드(Cloud function)으로 전달하는 Flask 웹 앱을 생성합니다.
2. Flask 웹 앱을 Dockerize 하여 Container Registry 에 push 합니다.
1. Google Cloud API를 호출해 이미지에서 텍스트를 추출합니다.(Cloud Vision)
2. 추출한 텍스트를 활용해 번역 API를 호출합니다.(Cloud Translation)
3. 번역된 내용을 Flask 웹 앱에 전달합니다.(Cloud Run)
Gemini Pro 와 같은 멀티모달 Gen AI를 활용해도 비슷한 결과가 나오지만, 이것은 자연어 처리와 복잡한 상호 작용이 필요하지 않고 In / Out으로 필요한 것이 아주 명확하기 때문에 Vision API와 Translate API를 활용했습니다.
(Vision API는 한 달에 1000개의 무료 호출을 허용하고, Translate API는 한 달에 처음 50만 개의 문자를 무료로 번역 가능합니다.)
코드의 구조는 아래과 같습니다.
└── image-text-translator
├── scripts/ - 환경 설정 및 도우미 스크립트
|└── setup.sh - 설정 도우미 스크립트
├── app/ - 애플리케이션
│ ├── ui_cr/ - 브라우저 UI(Cloud Run)
│ │ ├── static/ - 프런트엔드용 정적 콘텐츠
| | ├── templates/ - 프런트엔드용 HTML 템플릿
| | ├── app.py - Flask 애플리케이션
| | ├── requirements.txt - UI Python requirements
| | ├── Dockerfile - Flask 컨테이너를 빌드하는 Dockerfile
| | └── .dockerignore - Dockerfile에서 무시할 파일
| |
│ └── backend_gcf/ - 백엔드(클라우드 함수)
│ ├── main.py - 백엔드 CF 애플리케이션
│ └── requirements.txt - 백엔드 CF Python 요구 사항
├── requirements.txt - 프로젝트 로컬 개발에 대한 Python 요구 사항
└── README.md
1. Google Cloud에서 프로젝트를 만들고 API를 활성화 합니다.
# Google Cloud에 인증
gcloud auth list
# 올바른 프로젝트를 선택했는지 확인
export PROJECT_ID=<프로젝트 ID 입력>
gcloud config set project $PROJECT_ID
# Cloud Build API 사용
gcloud services enable cloudbuild.googleapis.com
# Cloud Storage API 사용
gcloud services enable storage-api.googleapis.com
# Artifact Registry API 사용
gcloud services enable artifactregistry.googleapis.com
# Eventarc API 사용
gcloud services enable eventarc.googleapis.com
# Cloud Run Admin API 사용
gcloud services enable run.googleapis.com
# Cloud Logging API 사용
gcloud services enable logging.googleapis.com
# Cloud Pub/Sub API 사용
gcloud services enable pubsub.googleapis.com #
Cloud Functions API
사용 gcloud services enable cloudfunctions.googleapis.com
# Cloud Translation API 사용
gcloud services enable translate.googleapis.com
# Cloud Vision API 사용
gcloud services enable vision.googleapis.com
# 서비스 계정 자격 증명 API 사용
gcloud services enable iamcredentials.googleapis.com
2. 인증 및 권한 부여를 해야 함.(Cloud Run은 Cloud Function에 인증해야 하고 Cloud Function은 Cloud Vision, Translation API에 인증해야 함)
# 이 작업을 하기 전에 PROJECT_ID 변수가 설정되어 있는지 확인하세요!
export SVC_ACCOUNT=image-text-translator-sa
export SVC_ACCOUNT_EMAIL= $SVC_ACCOUNT @ $PROJECT_ID .iam.gserviceaccount.com
# 사용자 관리 서비스 계정을 연결하는 것은 Google Cloud에서 실행되는 프로덕션 코드에 대한 ADC에 자격 증명을 제공하는 가장 좋은 방법입니다.
gcloud iam service-accounts create $SVC_ACCOUNT
3. 이제 서비스 계정의 여러 역할들을 묶어주겠습니다.
# 서비스 계정에 역할 부여
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SVC_ACCOUNT_EMAIL" \
--role=roles/run.admin
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SVC_ACCOUNT_EMAIL" \
--role=roles/run.invoker
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SVC_ACCOUNT_EMAIL" \
--role=roles/cloudfunctions.admin
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SVC_ACCOUNT_EMAIL" \
--role=roles/cloudfunctions.invoker
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SVC_ACCOUNT_EMAIL" \
--role="roles/cloudtranslate.user"
# 서비스 계정을 다른 리소스에 연결할 주체에게 필요한 역할을 부여합니다.
gcloud iam service-accounts add-iam-policy-binding $SVC_ACCOUNT_EMAIL \
--member="group:gcp-devops@my-org.com" \
--role=roles/iam.serviceAccountUser
# 서비스 계정 허용
gcloud iam service-accounts add-iam-policy-binding $SVC_ACCOUNT_EMAIL \
--member="group:gcp-devops@my-org.com" \
--role=roles/iam.serviceAccountTokenCreator
# 계정에 Cloud Functions 및 Cloud Run에 배포할 수 있는 액세스 권한이 있는지 확인합니다.
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="group:gcp-devops@my-org.com" \
--role roles/run.admin
4. 로컬 개발 환경을 열고 GCP와 연결합니다.
# 로컬 Linux 환경에 Google Cloud CLI를 설치합니다.
# https://cloud.google.com/sdk/docs/install을 참조하세요. #
Gcloud CLI에서 Python 및 pip를 설정합니다.
# https://cloud.google.com/python/docs/setup을 참조하세요.
# 로컬 개발자를 위한 추가 Google Cloud CLI 패키지를 설치합니다.
sudo apt install google-cloud-cli-gke-gcloud-auth-plugin kubectl google-cloud-cli-skaffold google-cloud-cli-minikube
# Google Cloud에 인증합니다.
gcloud auth login
5. git 을 복사하고 가상환경을 생성해 필요한 라이브러리를 설치합니다.
git clone https://github.com/hanhyeonkyu/image-text-translator.git
cd image-text-translator
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt
6. 앱 기본 자격 증명(ADC) 설정
ADC는 인증 라이브러리가 환경에 따라 자동으로 자격 증명을 찾을 수 있도록 하는 설정입니다. 로컬 환경과 Google Cloud의 대상 환경에서 모두 ADC를 활용할 수 있습니다.
ADC는 서비스 계정 자격 증명을 사용하도록 구성할 수 있습니다.
Cloud Run에서 Cloud Function 호출을 인증할 때, ADC를 가리킬 수 있는 서비스 계정 키를 만들었습니다.
gcloud auth application-default login
# 아직 설정하지 않은 경우...
export SVC_ACCOUNT=image-text-translator-sa
export SVC_ACCOUNT_EMAIL=$SVC_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
# 로컬 개발자를 위한 서비스 계정 키 생성
gcloud iam service-accounts keys create ~/.config/gcloud/$SVC_ACCOUNT.json \
--iam-account=$SVC_ACCOUNT_EMAIL
# 클라이언트 라이브러리에서 자동으로 감지되는 ADC 환경변수
export GOOGLE_APPLICATION_CREDENTIALS=~/.config/gcloud/$SVC_ACCOUNT.json
7. 모든 터미널에서 설정해야 하는 명령들
export PROJECT_ID=$(gcloud config list --format='value(core.project)')
export REGION=europe-west4
export SVC_ACCOUNT=image-text-translator-sa
export SVC_ACCOUNT_EMAIL=$SVC_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
export GOOGLE_APPLICATION_CREDENTIALS=~/.config/gcloud/$SVC_ACCOUNT.json
# Functions
export FUNCTIONS_PORT=8081
export BACKEND_GCF=https://$REGION-$PROJECT_ID.cloudfunctions.net/extract-and-translate
# Flask
export FLASK_SECRET_KEY=some-secret-1234
export FLASK_RUN_PORT=8080
echo "Environment variables configured:"
echo PROJECT_ID="$PROJECT_ID"
echo REGION="$REGION"
echo SVC_ACCOUNT_EMAIL="$SVC_ACCOUNT_EMAIL"
echo BACKEND_GCF="$BACKEND_GCF"
echo FUNCTIONS_PORT="$FUNCTIONS_PORT"
echo FLASK_RUN_PORT="$FLASK_RUN_PORT"
main.py에 아래 함수를 만듭니다. extract_and_translate가 Cloud Functions에 진입점 역할을 합니다.
@functions_framework.http
def extract_and_translate(request):
"""Extract and translate the text from an image.
The image can be POSTed in the request, or it can be a GCS object reference.
If a POSTed image, enctype should be multipart/form-data and the file named 'uploaded'.
If we're passing a GCS object reference, content-type should be 'application/json',
with two attributes:
- bucket: name of GCS bucket in which the file is stored.
- filename: name of the file to be read.
"""
# Check if the request method is POST
if request.method == 'POST':
# Get the uploaded file from the request
uploaded = request.files.get('uploaded') # Assuming the input filename is 'uploaded'
to_lang = request.form.get('to_lang', "en")
print(f"{uploaded=}, {to_lang=}")
if not uploaded:
return flask.jsonify({"error": "No file uploaded."}), 400
if uploaded: # Process the uploaded file
file_contents = uploaded.read() # Read the file contents
image = vision.Image(content=file_contents)
else:
return flask.jsonify({"error": "Unable to read uploaded file."}), 400
else:
# If we haven't created this, then get it from the bucket instead
content_type = request.headers.get('content-type', 'null')
if content_type == 'application/json':
bucket = request.json.get('bucket', None)
filename = request.json.get('filename', None)
to_lang = request.json.get('to_lang', "en")
print(f"Received {bucket=}, {filename=}, {to_lang=}")
else:
return flask.jsonify({"error": "Unknown content type."}), 400
if bucket:
image = vision.Image(source=vision.ImageSource(gcs_image_uri=f"gs://{bucket}/{filename}"))
# Use the Vision API to extract text from the image
detected = detect_text(image)
if detected:
translated = translate_text(detected, to_lang)
if translated["text"] != "":
# print(translated)
return translated["text"]
return "No text found in the image."
- POST 를 받았는지 체크하고, uploaded 객체를 찾은 뒤 이를 이진수로 읽어 vision.Image 객체를 생성합니다.
- 다음으로 이미지를 전달할 함수를 호출합니다.(detect_text)
def detect_text(image: vision.Image) -> dict | None:
"""Extract the text from the Image object """
text_detection_response = vision_client.text_detection(image=image)
annotations = text_detection_response.text_annotations
if annotations:
text = annotations[0].description
else:
text = ""
# print(f"Extracted text from image:\n{text}")
# Returns language identifer in ISO 639-1 format. E.g. en.
# See https://en.wikipedia.org/wiki/List_of_ISO_639_language_codes
detect_language_response = translate_client.detect_language(text)
src_lang = detect_language_response["language"]
print(f"Detected language: {src_lang}.")
message = {
"text": text,
"src_lang": src_lang,
}
return message
이미지 속의 텍스트를 감지하고 Google 언어 API를 사용해 텍스트의 언어가 어느 나라 언어인지도 판별합니다.
다음으로 translate_text 기능입니다.
def translate_text(message: dict, to_lang: str) -> dict:
"""
Translates the text in the message from the specified source language
to the requested target language, then sends a message requesting another
service save the result.
"""
text = message["text"]
src_lang = message["src_lang"]
translated = { # before translating
"text": text,
"src_lang": src_lang,
"to_lang": to_lang,
}
if src_lang != to_lang and src_lang != "und":
print(f"Translating text into {to_lang}.")
translated_text = translate_client.translate(
text, target_language=to_lang, source_language=src_lang)
translated = {
"text": unescape(translated_text["translatedText"]),
"src_lang": src_lang,
"to_lang": to_lang,
}
else:
print("No translation required.")
return translated
언어 감지를 통해 src_lang을 파악했고 to_lang을 통해 어느 나라 언어로 번역할지를 선택한 뒤 Google Translate API를 사용해 번역합니다.
로컬에서 테스트하려면 backend-gcf 폴더에서 명령을 실행하세요.
# Run the function
functions-framework --target extract_and_translate \
--debug --port $FUNCTIONS_PORT
이미지로 테스트 해보려면 아래와 같이 실행하세요.(원하는 이미지를 이용하세요.)
# You will first need to authenticate and set the environment vars in this terminal
source ./scripts/setup.sh
# now invoke
curl -X POST localhost:$FUNCTIONS_PORT \
-H "Content-Type: multipart/form-data" \
-F "uploaded=@./testing/images/kr_meme.jpg" \
-F "to_lang=en"
실행된 것을 확인할 수 있습니다.
backend-gcf 폴더에서 아래 명령을 실행하세요.
# From the backend-gcf folder
gcloud functions deploy extract-and-translate \
--gen2 --max-instances 1 \
--region $REGION \
--runtime=python312 --source=. \
--trigger-http --entry-point=extract_and_translate \
--no-allow-unauthenticated
# Allow this function to be called by the service account
gcloud functions add-invoker-policy-binding extract-and-translate \
--region=$REGION \
--member="serviceAccount:$SVC_ACCOUNT_EMAIL"
VS Code의 Cloud Code 확장 기능을 사용하면 배포된 Cloud Function 을 직관적으로 확인할 수 있습니다.
이제 Cloud Function에서 확인해 봅니다.
curl -X POST https://$REGION-$PROJECT_ID.cloudfunctions.net/extract-and-translate \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H "Content-Type: multipart/form-data" \
-F "uploaded=@./testing/images/ua_meme.jpg" \
-F "to_lang=en"
잘 작동되는 것을 확인할 수 있습니다.
Cloud Function에 버전을 업데이트 하고 싶다면 deploy 명령을 다시 실행하면 됩니다.
또한 Cloud Function을 삭제하려면 아래와 같이 실행하세요.
gcloud functions delete extract-and-translate --region=$REGION
이제 Cloud Run 에 Flask Web APP을 배포해야 하는데요.
Flask Web App은 단순히 이미지를 업로드하고 Cloud Function에 요청하는 것이니 Github 코드를 참고하세요.
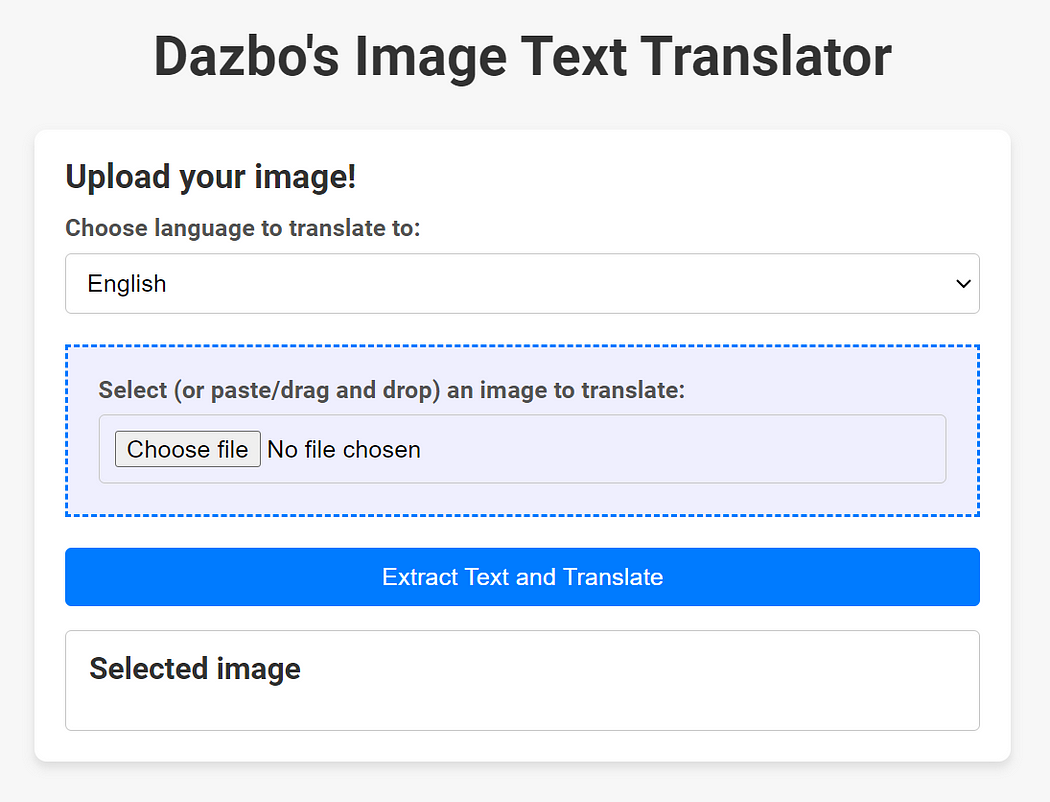
이제 Cloud Run에 배포합니다.
Flask Web App을 Google Artifact Registry(GAR)에 저장하기 위해 저장소를 먼저 생성합니다.
Cloud Build를 사용해 소스에서 컨테이너 이미지를 빌드하고 GAR에 저장합니다.
GAR의 이미지를 참조해 Cloud Run에서 배포합니다.
그럼 먼저 이미지를 빌드해 줍니다.
export IMAGE_NAME=$REGION-docker.pkg.dev/$PROJECT_ID/image-text-translator-artifacts/image-text-translator-ui
# configure Docker to use the Google Cloud CLI to authenticate requests to Artifact Registry.
gcloud auth configure-docker $REGION-docker.pkg.dev
# Build the image and push it to Artifact Registry
# Run from the ui_cr folder
gcloud builds submit --tag $IMAGE_NAME:v0.1 .
이제 이미지를 Cloud Run으로 배포합니다.
# create a random secret key for our Flask application
export RANDOM_SECRET_KEY=$(openssl rand -base64 32)
gcloud run deploy image-text-translator-ui \
--image=$IMAGE_NAME:v0.1 \
--region=$REGION \
--platform=managed \
--allow-unauthenticated \
--max-instances=1 \
--service-account=$SVC_ACCOUNT \
--set-env-vars BACKEND_GCF=$BACKEND_GCF,FLASK_SECRET_KEY=$RANDOM_SECRET_KEY
새 버전의 배포를 원한다면 아래와 같이 하면 됩니다.
# Check our IMAGE_NAME is set
export IMAGE_NAME=$REGION-docker.pkg.dev/$PROJECT_ID/image-text-translator-artifacts/image-text-translator-ui
# Set our new version number
export VERSION=v0.2
# Rebuild the container image and push to the GAR
gcloud builds submit --tag $IMAGE_NAME:$VERSION .
# create a random secret key for our Flask application
export RANDOM_SECRET_KEY=$(openssl rand -base64 32)
# Redeploy
gcloud run deploy image-text-translator-ui \
--image=$IMAGE_NAME:$VERSION \
--region=$REGION \
--platform=managed \
--allow-unauthenticated \
--max-instances=1 \
--service-account=$SVC_ACCOUNT \
--set-env-vars BACKEND_GCF=$BACKEND_GCF,FLASK_SECRET_KEY=$RANDOM_SECRET_KEY
자동으로 생성된 DNS가 있지만 미리 준비된 다른 도메인과 맵핑하려면 아래와 같습니다.
# Verify your domain ownership with Google
gcloud domains verify mydomain.com
# Check it
gcloud domains list-user-verified
# Create a mapping to your domain
gcloud beta run domain-mappings create \
--region $REGION \
--service image-text-translator-ui \
--domain image-text-translator.mydomain.com
# Obtain the DNS records. We want everything under `resourceRecords`.
gcloud beta run domain-mappings describe \
--region $REGION \
--domain image-text-translator.mydomain.com
이제 맵핑한 도메인에서 서비스가 운영되고 있는 것을 확인할 수 있습니다.
AI를 배우고 싶어 2024년에 어떻게 해야 할지 리서치 해보면서 글을 작성해 봤습니다.
AI를 정말로 배우기 위해서는 튜토리얼 지옥을 탈출하고 정말 배우고, 실습하고, 알고리즘을 작성하고, 논문을 구현하며, AI를 사용해 문제를 해결하는 사이드 프로젝트를 수행해야 합니다.
이제 AI를 공부하는 방식을 생각해 보면,
필요에 따라 배우는 것을 할 줄 알아야 합니다. 모든 것을 배우려면 한 개를 배우기에도 너무 깊은 분야이기에 필요에 따라 필요한 것들을 특정해 배워나가야 합니다.
그렇게 하려면 코드 우선, 이론 나중에로 진행하게 할 겁니다.
AI를 사용하려면 배워야 할 것이 많고 새로운 혁명적인 논문과 아이디어가 매주 발표되니 학습해야 할 것이 끝이 없습니다.
그렇게 때문에 개인적으로 배우는 것은 가장 큰 실수입니다. 그렇게 하면 스스로에게 어떤 기회도 창출되지 않고 뭔가 완료했다고 말 할 수 있는 것 외에는 보여줄 것이 없습니다.
중요한 것은 무엇을 만들었고, 그것을 대중과 공유할 지식으로 어떻게 전환시켰고, 그 정보에서 어떤 참신한 아이디어와 솔루션이 나왔는가이기 때문입니다. 그래서 공개적으로 배워야 합니다!
블로그, 튜토리얼을 작성하거나 해커톤에 참여하며 다른 사람들과 협력하고, Discord 커뮤니티에서 질문하고 답변하고 사이드 프로젝트에 참여하세요!
이제 본격적으로 시작해 보겠습니다!

우선 수학을 알아야 합니다. 머신 러닝은 선형 대수학, 미적분학, 확률, 통계라는 수학의 세 가지 요소에 크게 의존합니다. 각각은 알고리즘이 효과적으로 작동하도록 하는 데 고유한 역할을 합니다.
프로그래머의 관점에서 ML을 위한 수학에 대한 훌륭한 시리즈입니다. 가중치 및 편향을 통한 기계 학습을 위한 수학 ( 코드 )
선형 대수학에 대한 코드 우선 접근 방식을 원한다면 fast.ai 제작자가 만든 전산 선형 대수학 ( 비디오 , 코드 )을 수행하세요.
과정과 함께 Python을 사용한 응용 기계 학습을 위한 선형 대수학 소개를 읽어보세요.
좀 더 전통적인 것을 원한다면 Imperial College London 강의 인 선형 대수학 및 다변량 미적분학을 살펴보십시오.
3Blue1Brown의 선형 대수학의 본질 과 미적분학의 본질을 시청하세요.
통계를 보려면 StatQuest의 통계 기초를 시청하세요.
보충

파이썬
초보자는 여기서 시작하세요: 실용적인 Python 프로그래밍
이미 Python에 익숙하다면 고급 Python 마스터리를 수행하세요.
둘 다 Python Cookbook의 저자인 David Beazley가 만든 훌륭한 강좌입니다.
그 후 James Powell의 강연을 시청해 보세요.
Python 디자인 패턴을 읽어보세요 .
보충
파이토치
Aladdin Persson 의 PyTorch 튜토리얼 보기
PyTorch 웹사이트는 훌륭한 곳입니다.
몇 가지 퍼즐로 지식을 테스트해보세요
보충

100페이지 분량의 ML 책을 읽어보세요.
읽는 동안 알고리즘을 처음부터 작성하세요.
아래 저장소를 살펴보세요
도전해보고 싶다면 이 과정을 따라 처음부터 PyTorch를 작성해 보세요.
배운 내용을 대회에서 적용해 보세요.
Vicki Boykis의 기계 학습을 프로덕션에 적용하기를 읽어보세요 .
그녀는 또한 책에 대한 의미론적 검색인 Viberary를 구축하면서 배운 내용에 대해 썼습니다 .
데이터 세트를 얻고 모델을 구축합니다(즉, Earthaccess를 사용하여 NASA 지구 데이터를 얻습니다).
Streamlit을 사용하여 UI를 만들고 Twitter에서 공유하세요.
생산 중인 모델을 가져옵니다. 실험을 추적하세요. 모델을 모니터링하는 방법을 알아보세요. 데이터와 모델 드리프트를 직접 경험해보세요.
다음은 몇 가지 훌륭한 리소스입니다.

문제를 해결하기 위해 코드 먼저 배우고 이론 배우기를 원한다면 fast.ai로 시작해 보세요.
fast.ai를 좋아하시나요? 풀스택 딥러닝을 확인해 보세요 .
보다 포괄적이고 전통적인 과정을 원한다면 François Fleuret 의 UNIGE 14x050 — 딥 러닝을 확인하세요 .
어느 시점에서 이론에 도달해야 한다면 이 책은 훌륭한 책입니다.
트위터를 스크롤하는 대신 휴대폰에서 The Little Book of Deep Learning을 읽어보세요 .
신경망이 수렴되는 동안 이 내용을 읽어보세요.
labml.ai 주석이 달린 PyTorch 종이 구현을 확인해 보세요.
Papers with Code는 훌륭한 리소스입니다. 여기 웹사이트에 BERT가 설명되어 있습니다 .
다음은 딥 러닝 내 전문 분야에 대한 몇 가지 리소스입니다.
많은 사람들이 CS231n: Deep Learning for Computer Vision을 추천합니다 . 어렵지만 이겨낸다면 그만한 가치가 있습니다.
RL의 경우 다음 두 가지가 훌륭합니다.
또 다른 훌륭한 스탠포드 코스, CS 224N | 딥러닝을 통한 자연어 처리
포옹 얼굴 배우기: 포옹 얼굴 NLP 과정
이 Super Duper NLP Repo를 확인하십시오.
좋은 기사와 고장
보충
먼저 Andrew의 [ 1시간 토크] 대규모 언어 모델 소개를시청하세요 .
Then Large Language Models in Five Formulas , 작성자: Alexander Rush — Cornell Tech
역전파를 처음부터 설명하고 코딩하는 것으로 시작하여 처음부터 GPT를 작성하는 것으로 끝납니다.
신경망: Zero To Hero 저: Andrej Karpathy
방금 새 동영상을 공개했습니다. → GPT Tokenizer를 만들어 보겠습니다.
NumPy의 60줄에서 GPT를볼 수도 있습니다 .당신이 그것에 있는 동안 Jay Mody
Full Stack Deep Learning에서 무료로 출시한 유료 LLM Bootcamp 입니다.
프롬프트 엔지니어링, LLMOps, LLM용 UX 및 한 시간 안에 LLM 앱을 시작하는 방법을 가르칩니다.
이제 이 부트 캠프를 마친 후 빌드하고 싶으므로
LLM으로 앱을 구축하고 싶으신가요?
Andrew Ng의 대규모 언어 모델을 사용한 애플리케이션 개발 보기
Huyen Chip의 생산용 LLM 애플리케이션 구축 읽기
Eugene Yan의 LLM 기반 시스템 및 제품 구축을 위한 패턴
레시피는 OpenAI Cookbook을 참조하세요 .
Vercel AI 템플릿을 사용하여 시작하세요.
lablab.ai에서는 매주 새로운 AI 해커톤이 열립니다. 팀을 이루고 싶다면 알려주세요 !
이론에 더 깊이 들어가 모든 것이 어떻게 작동하는지 이해하고 싶다면:
대형 언어 모델 이해 에 관한 Sebastian Raschka 의 훌륭한 기사로 , 읽어야 할 몇 가지 논문을 나열합니다.
그는 또한 최근 미스트랄 모델을 다루는 2024년 1월에 읽어야 할 논문이 포함된 또 다른 기사를 발표했습니다 .
AI보다 앞서서 그의 서브스택을 따라가세요 .
Transformer 제품군 버전 2.0 읽기 | 개요를 보려면 Lil'Log를참조하세요.
가장 적합한 형식을 선택하고 처음부터 구현하세요.
종이
블로그
비디오
이제 변환기를 처음부터 코딩할 수 있습니다. 하지만 아직 더 많은 것이 있습니다.
Stanford CS25 — Transformers United동영상을 시청하세요.
그는 논문을 설명하는 환상적이고 심층적인 비디오를 보유하고 있습니다. 그는 또한 코드를 보여줍니다.
완전하지 않은 LLM과 관련된 추가 링크. LLM에 대한 보다 포괄적인 강의 계획서를 보려면 LLM 강의 계획서를 살펴보세요 .
ollama 사용 : Llama 2, Mistral 및 기타 대규모 언어 모델을 로컬에서 시작 및 실행
그들은 최근 Python 및 JavaScript 라이브러리를 출시했습니다.
프롬프트 엔지니어링 읽기 | 릴로그
Ise Fulford(OpenAI) 및 Andrew Ng의 개발자를 위한 ChatGPT 프롬프트 엔지니어링
DeepLearning.ai 에는 무료로 등록할 수 있는 다른 단기 강좌도 있습니다.
포옹 얼굴 미세 조정 가이드를 읽어보세요 .
좋은 가이드북: 미세 조정 — GenAI 가이드북
axolotl을 확인해보세요 .
이것은 좋은 기사입니다: Direct Preference Optimization을 사용하여 Mistral-7b 모델 미세 조정 | 막심 라본느
Anyscale의 훌륭한 기사: 프로덕션용 RAG 기반 LLM 애플리케이션 구축
Aman Chadha 의 검색 증강 생성 에 대한 포괄적인 개요
뉴스레터 + 팟캐스트 + 트위터의 결합
논문은 AK(@_akhaliq)를 팔로우하세요.
팟캐스트 중 내가 찾은 최고는 Swyx & Alessio의 Latent Space 입니다.
그들의 불화에 동참하세요 .
또한 모든 대규모 AI 불일치를 요약한 뉴스레터 Smol Talk 도 있습니다 .
내가 좋아하는 다른 뉴스레터는 다음과 같습니다.
이 기사 에서 더 많은 정보를 얻으세요 .
내 목록은 완전한 목록은 아니지만, 그래도 더 많은 것을 찾고 싶다면 여기 몇 가지를 참조하세요.
모두에게 AI 여정에 도움이 되기를 바랍니다.