Your Jenkins data directory /var/lib/jenkins (AKA JENKINS_HOME) is almost full. You should act on it before it gets completely full.
· One min read
갑자기 jenkins 가 빌드가 안된다.
뭔가 가득 찼다는 말 같아, 빌드 서버에 접속해 확인을 해보니(우분투 서버)
df -h 를 입력해 용량을 확인하면 용량이 100% 차 있는 곳이 많이 있다.
build 서버에서 용량이 자꾸 늘어날 이유가 무엇일까 생각 중 로컬 랩탑에서 docker 빌드하면 남는 큰 용량의 dangling image들이 생각났다. 내 랩탑은 매번 disk에서 지워주지만 서버는 신경을 못 썼다...
그래서 확인해 해 봤다! docker image ls
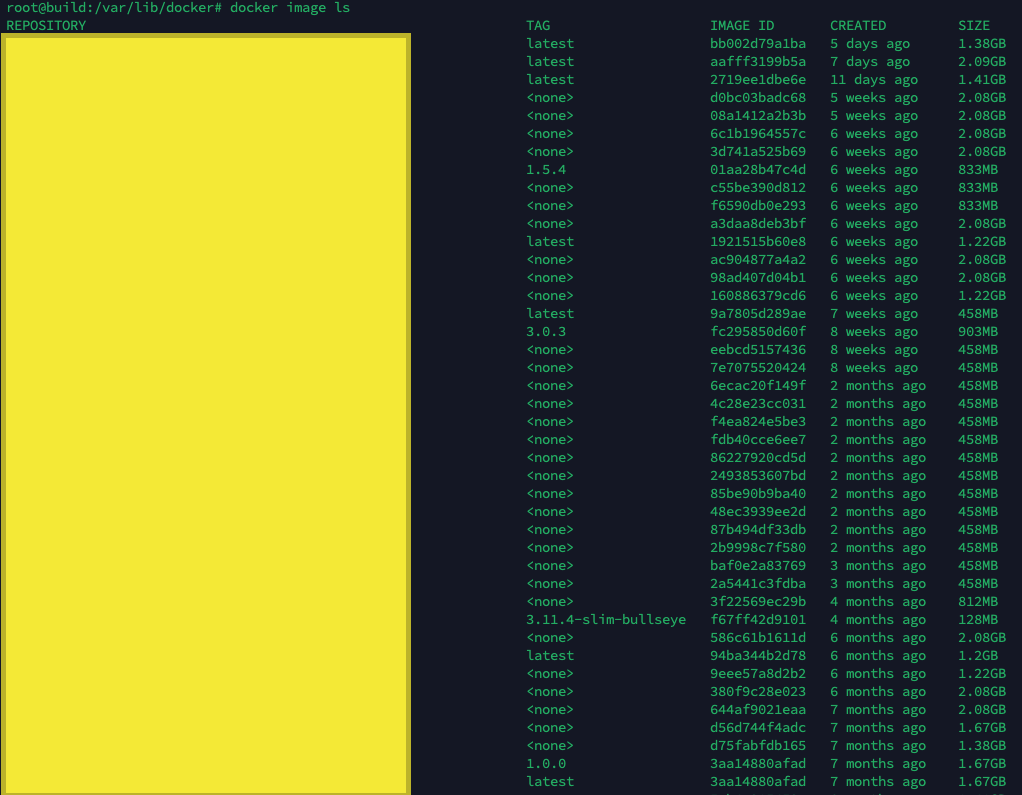
끝을 모르고 쌓여 있는 이미지들...
docker rmi $(docker images -f "dangling=true" -q)
를 입력해 모두 제거했다.
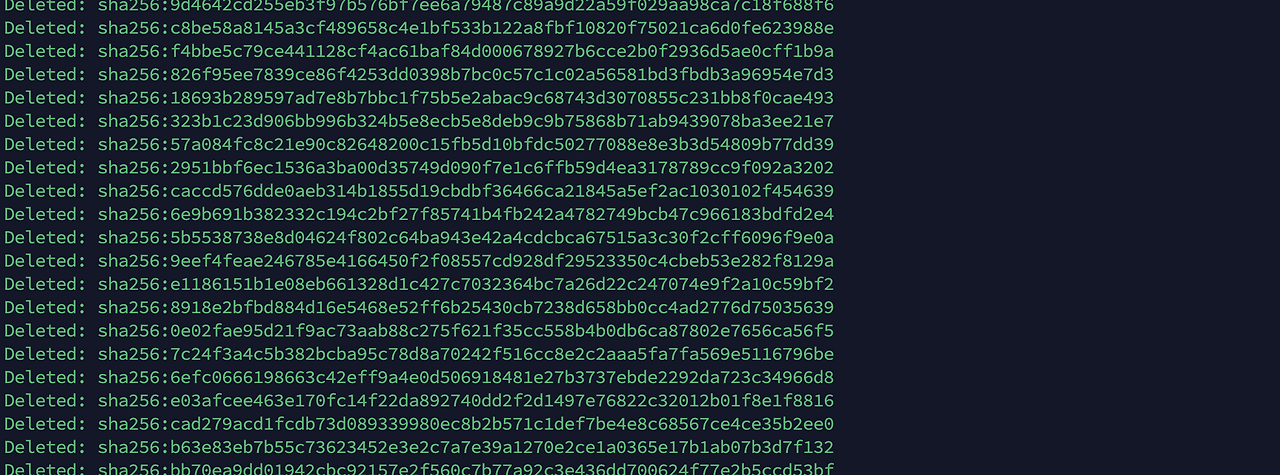
눈 앞에서 마구 삭제하니 불안한 마음이 생기지만 실행중인 컨테이너도 아니고 이미지니까 괜찮겠지 하며 기다려 본다...
완료 후 확인해 보니 아래와 같이 용량이 확보됐고 빌드가 정상 실행됐다.
