How To Move Database Files To New Volume In MSSQL Server


IT 계열로 넘어온 후 스타트업을 전전하다가 재택근무를 위해 이직을 하다가 갑자기 꽤 큰 규모의 회사에 들어왔다.
스타트업은 개발자들이 입사를 잘 하지 않아 생각보다 많은 우대를 해줬구나를 느낀다.
지금 다니는 회사는 개발이 메인인 회사가 아니다 보니 사실 서비스를 엑셀로도 제공하기도 하고 그런다...;
스타트업에서는 돈을 아끼기 위해서인지 무료 데이터베이스들만 사용해 왔다. Postgresql, Mysql, MongoDB 이런 데이터베이스들에 익숙해진 상태였다. 서버도 항상 리눅스 계열의 서버만 이용했고 사실 그마저도 중요하지 않았던 건 데이터베이스들은 매니지드 데이터베이스 서비스들을 이용해 와서 알아서 관리되고 있었고 가끔 복구가 필요할 때 주기적으로 스냅샷 저장해 둔 것을 토대로 복구하면 됐다.
그러나 이 회사는 내가 해 온 개발과 결이 많이 달랐다. 모든 것이 수동이다. 데이터베이스 서버 구성도 수동으로 EC2 같은 서버를 띄워두고 데이터베이스도 볼륨에 저장해 둔 뒤 용량이 가득차면 새 볼륨을 만들어 다른 볼륨에 추가해주는 방식으로 운영되어 왔다.
이것 외에도 파일 storage를 따로 두지 않고 EC2 서버에 저장해 가며 쓰는 방식도, 사람들마다 다른 언어로 만들어 놓은 개발 구조도 모든 구조를 새로 마이그레이션 해야 하지만 그 이전에 운영을 위해 용량이 가득 찬 드라이브의 데이터베이스 파일들을 신규 드라이브에 옮겨 다시 데이터베이스와 연결해 주는 작업을 해야 했다.

먼저 해야 할 일은 클라우드 대시보드에서 볼륨을 추가해 주고 서버와 그 볼륨을 연결해 주는 작업이다. 이런 작업들은 대시보드를 제공하는 회사들에서는 메뉴얼로 제공해주는 형태가 보통이기 때문에 그리 어렵지 않게 해결된다.

이제 윈도우 서버로 돌아가보자. 윈도우 서버에서 제어판을 열고 관리도구 -> 컴퓨터 관리 -> 저장소 -> 디스크 관리 순서대로 따라 오면 방금 전 대시보드에서 추가한 신규 볼륨이 보입니다.
그럼 해당 디스크는 컴퓨터 입장에서 신규로 생긴 디스크이니 디스크 초기화 및 할당을 통해 내 컴퓨터에서 들어갈 수 있도록 만듭니다.
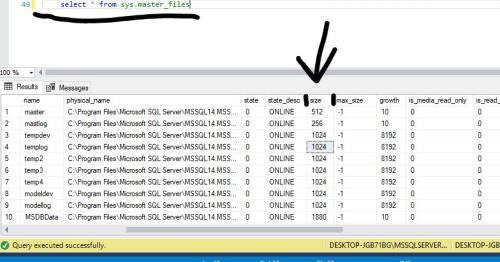
데이터베이스를 다시 살펴보면 sys.master_files 테이블을 조회해 보자. 여기서는 데이터베이스에 연결된 모든 파일들의 정보를 확인할 수 있다. 간단하게는 용량이 부족하다는 것을 알게 된 데이터베이스에서 마우스 오른쪽 클릭해 속성에 들어가면 어떤 파일에 연결되어 있고 max_size가 unlimited인지 limited인지 알 수 있다. (limited라면 디스크 용량을 확인하고 unlimited로 변경해 더 많이 디스크에 할당하면 됨)
일단 unlimited 상태라서 자동으로 디스크 할당이 증가하지만 그 디스크 용량 자체가 가득 찬 상태
라면 더 이상 늘릴 수 없는 상태가 된다.
이제 새로 생성한 볼륨에 데이터베이스 파일들(mdf, ldf)을 복사해 줄 때가 됐다.

우선 사전준비를 시작하자!
아까 확인한 데이터베이스 파일들이 있는 위치로 이동하고 새 디렉토리를 열어 데이터베이스 파일들을 옮길 폴더의 위치로 이동한다.
데이터베이스 파일들을 옮길 폴더 위에 마우스 오른쪽을 클릭해 속성 -> advanced -> security 에서 유저를 추가해 준다.
유저 추가 시 NT SERVICE\MSSQLSERVER 입력 후 이름 확인 후 OK 하고 적용해 준다.
그리고 복사하기 이전에 다시 데이터베이스 클라이언트로 가서 아래와 같이 코드를 입력해 준다.
# master로 실행해야 함
USE master
# 우선 데이터베이스를 오프라인시킴
ALTER DATABASE [데이터베이스 이름] SET OFFLINE
# 파일 위치를 변경함. 위의 과정 중 SQL에서 확인된 FileLogicalName을 활용해 이름 입력.
# 그리고 실제 복사한 데이터베이스 파일들의 속성 / advanced 에서 compress contents to save disk space 를 체크해제 해주는 것도 꼭 해야 함.
ALTER DATABASE [데이터베이스 이름] MODIFY FILE ( NAME='[데이터베이스 이름]', FILENAME='G:\SQLServer\DATA\[데이터베이스 이름].mdf' )
ALTER DATABASE [데이터베이스 이름] MODIFY FILE ( NAME='[데이터베이스 이름]_log', FILENAME='G:\SQLServer\DATA\[데이터베이스 이름]_log.ldf' )
# 데이터베이스 원상복귀
ALTER DATABASE [데이터베이스 이름] SET ONLINE;
이제 위의 코드에서 데이터베이스 오프라인까지 진행한 뒤,
원하는 폴더로 데이터베이스 파일들을 복사해 준다. 복사한 데이터베이스 파일들에서 하나씩 마우스 오른쪽을 클릭해 속성 -> advanced에서 compress contents to save disk space 를 체크 해제해 준다.
그런 뒤 위의 남은 쿼리들을 실행시켜 다시 정상화 해준다.
생각보다 간단하게 마무리 됐지만 데이터베이스 파일들을 옮겨 보는 일은 처음이고 데이터베이스 작업은 항상 신중히 진행해야 하기 때문에 시간이 오래 걸렸다. 다른 사람들은 이런 수고를 덜었으면 좋겠다.