BigQuery 데이터를 LangChain 앱에 통합하기

데이터는 모든 AI 솔루션에서 사용할 핵심 재료입니다.
평소 GCP 를 이용하는 편인데 BigQuery 를 통해 많은 로그들도 쌓고 많은 데이터들도 쌓는 편입니다.
요새 더 핫해진 LLM 어플리케이션에 BigQuery를 활용하려면 어떻게 해야 할까요?
이전에 설명했던 LangChain은 LLM과 같은 모델들을 어플리케이션에 쉽게 서빙할 수 있게 해주는 프레임워크입니다.
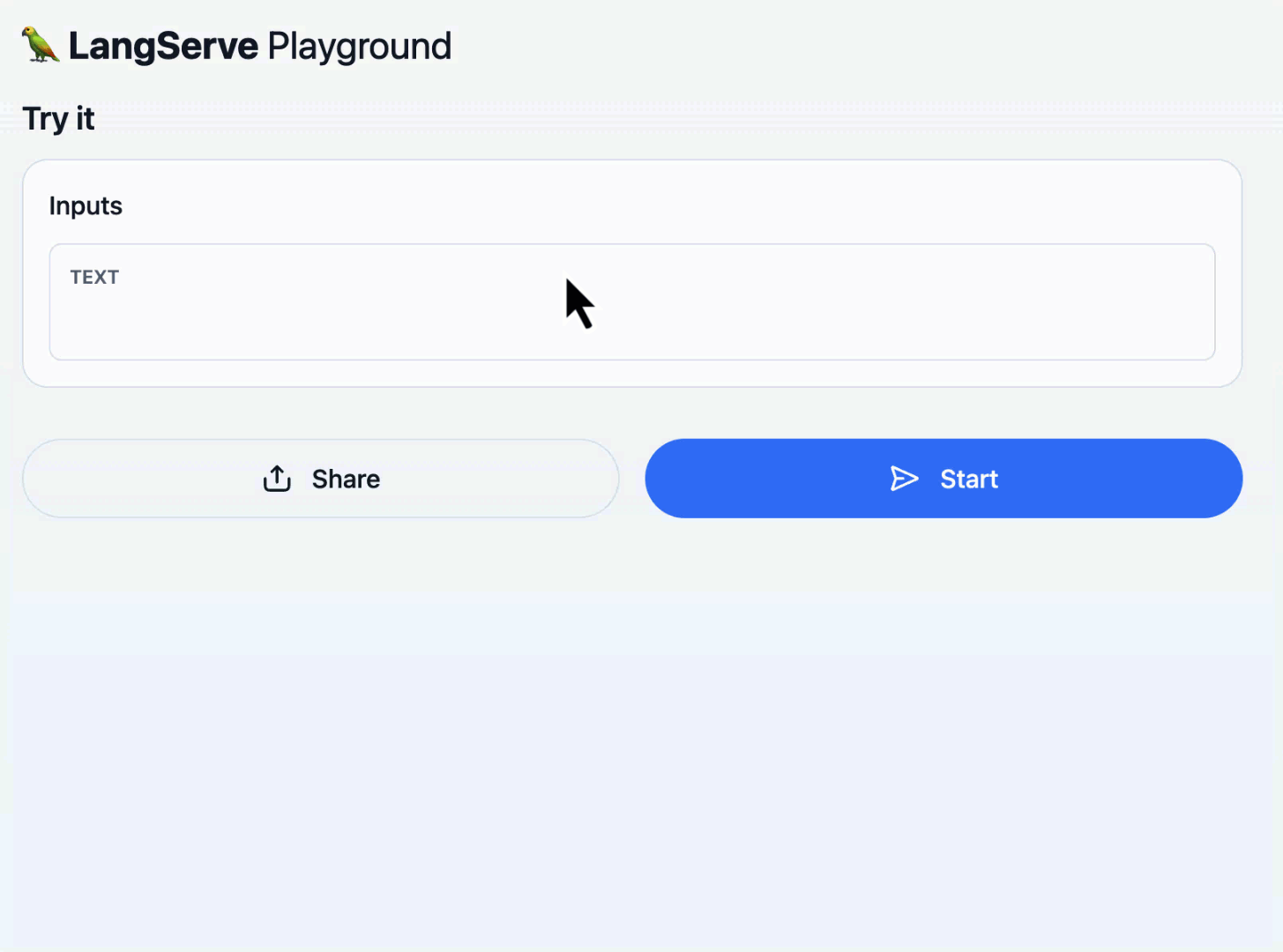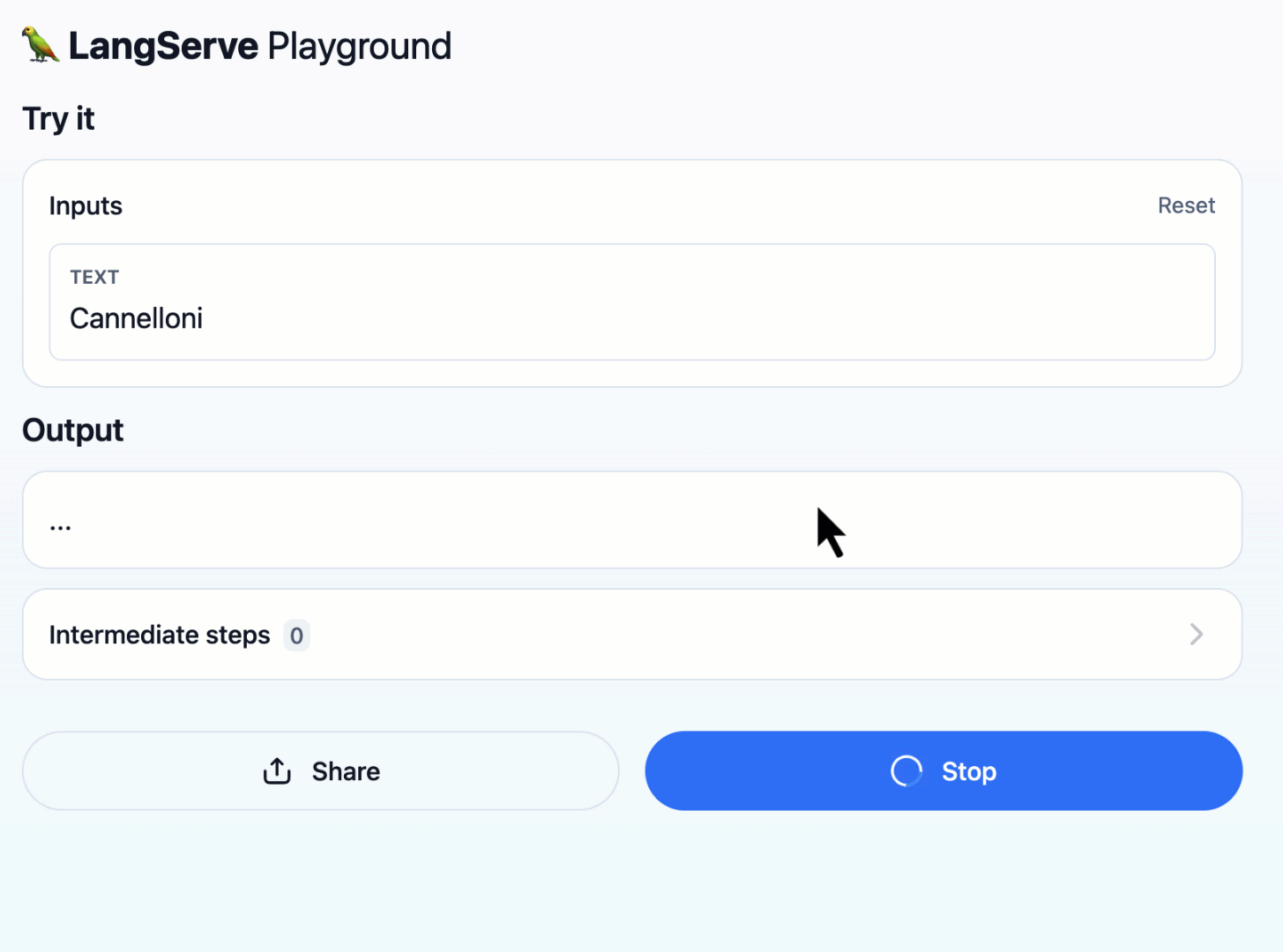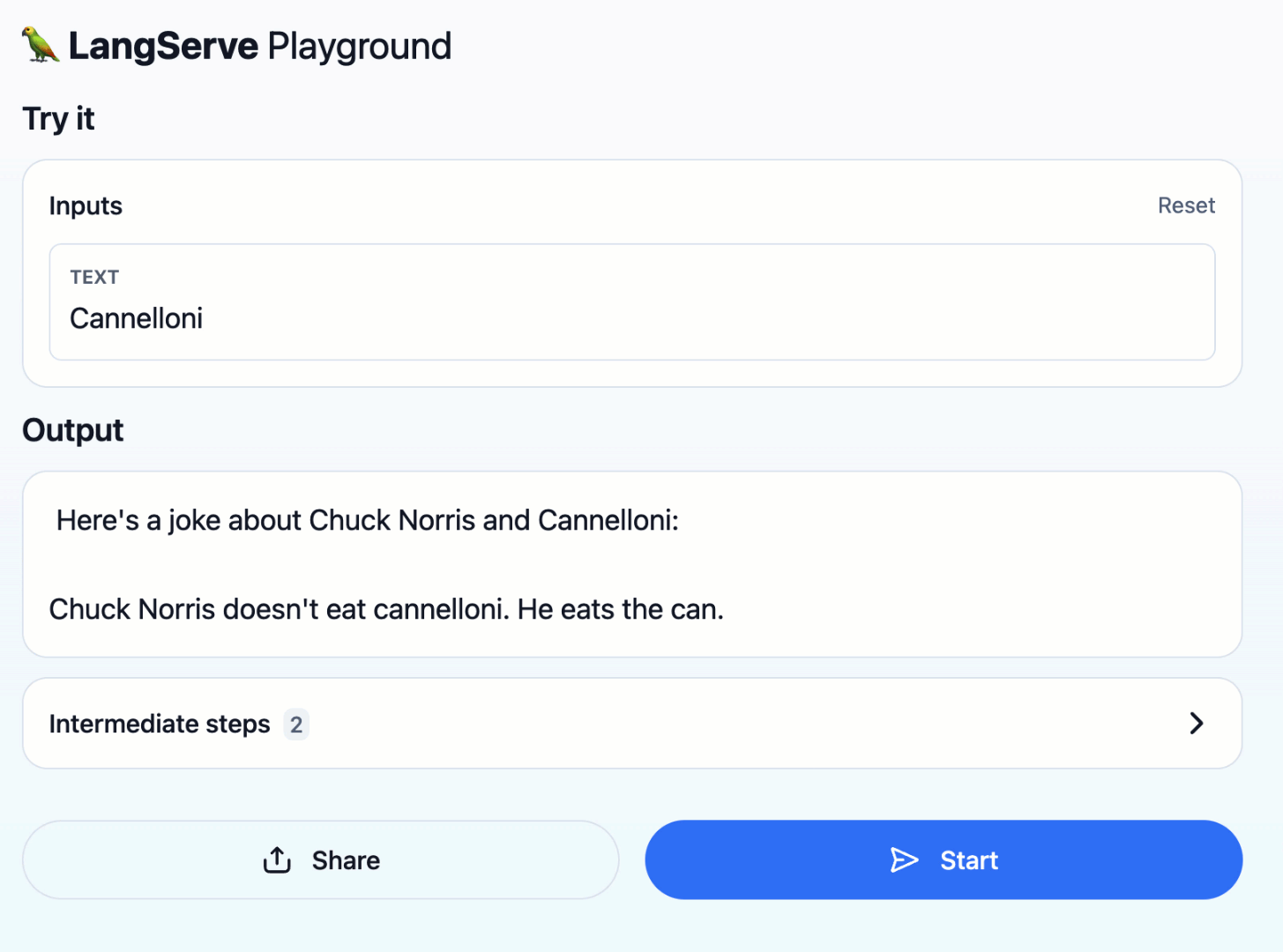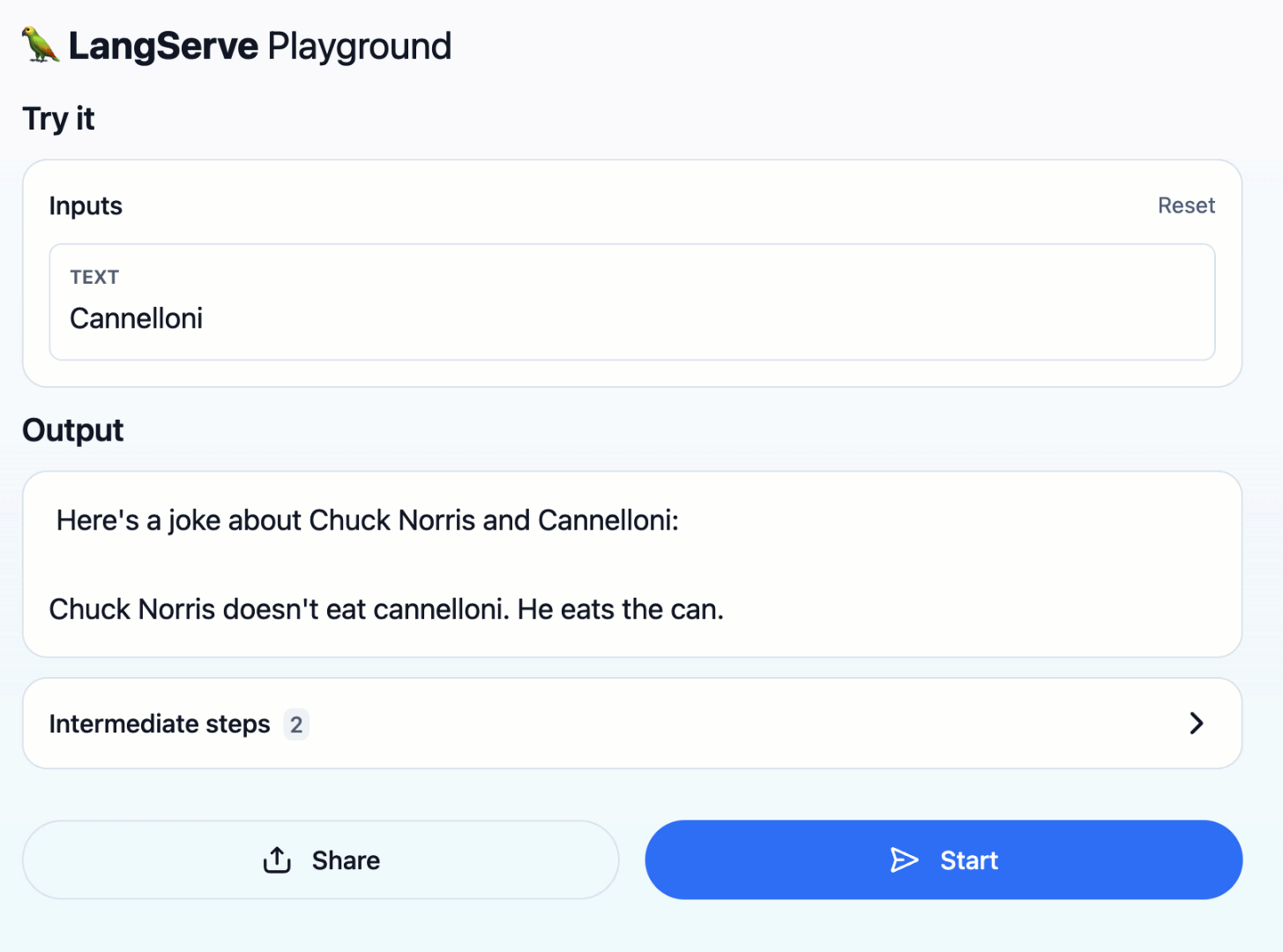
LangChain을 사용하면 모듈식 아키텍처와 사전 구축된 커넥터를 통해 LLM 개발을 단순화할 수 있습니다. BigQuery의 방대한 데이터를 LLM 모델에 사용해 어플리케이션에 이용할 수 있도록 하기 위해 LangChain의 BigQuery Data Loader를 사용하는 방법을 알아보려고 합니다.
LangChain 시작하기
우선 LangChain과 Vertex AI SDK 를 설치해 줍니다.
pip install --quiet google-cloud-aiplatform langchain
Vertex AI SDK를 시작해 주고 모델을 쿼리합니다.
# Initialize Vertex AI SDK
import vertexai
vertexai.init(project="<your-project-id>", location="us-central1")
# Query the model
from langchain.llms import VertexAI
llm = VertexAI(model_name="text-bison@001", temperature=0)
llm("What's BigQuery?")
LLM에게 BigQuery에 대해 문의하면 BigQuery에 대한 설명을 LLM으로 대신할 수 있습니다.
BigQuery는 기업이 모든 데이터를 매우 빠르게 분석할 수 있도록 지원하는 완전 관리형 페타바이트 규모의 분석 데이터 웨어하우스입니다. 빠른 성능, 확장성, 유연성을 제공하는 클라우드 기반 서비스입니다. BigQuery는 사용하기 쉽고 다른 Google Cloud Platform 서비스와 통합될 수 있습니다.
Data Loader 사용
우선 Big Query Library를 설치합니다.
pip install google-cloud-bigquery
이제 쿼리를 정의해 데이터를 로드해 보면
# Define our query
query = f"""
SELECT table_name, ddl
FROM `bigquery-public-data.thelook_ecommerce.INFORMATION_SCHEMA.TABLES`
WHERE table_type = 'BASE TABLE'
ORDER BY table_name;
"""
# Load the data
loader = BigQueryLoader(query, project="<your-project-id>", metadata_columns="table_name", page_content_columns="ddl")
data = loader.load()
쿼리는 각 테이블에 대한 테이블 이름과 DDL을 추출합니다.
loader.load()를 통해 데이터 변수에 데이터를 할당합니다.
첫 번째 Chain 작성
수행 방법은 다음과 같습니다. LCEL( LangChain Expression Language )을 사용하여 3단계로 체인을 정의합니다.
- 각 문서의 page_content (각 테이블의 DDL임을 기억하세요)를 content 라는 문자열로 결합하겠습니다 .
- 테이블 메타데이터의 결합된 세트인 콘텐츠를 전달하여 가장 가치 있는 고객을 찾기 위한 프롬프트를 만듭니다 .
- 프롬프트를 LLM에 전달합니다.
# Use code generation model
llm = VertexAI(model_name="code-bison@latest", max_output_tokens=2048)
# Define the chain
from langchain.prompts import PromptTemplate
from langchain.schema import format_document
chain = (
{
"content": lambda docs: "\n\n".join(
format_document(doc, PromptTemplate.from_template("{page_content}")) for doc in docs
)
}
| PromptTemplate.from_template("Suggest a query that will help me identify my most valuable customers, with an emphasis on recent sales:\n\n{content}")
| llm
)
# Invoke the chain with the documents, and remove code backticks
result = chain.invoke(data).strip('```')
print(result)
쿼리를 살펴보면
SELECT
users.id AS user_id,
users.first_name AS first_name,
users.last_name AS last_name,
users.email AS email,
SUM(order_items.sale_price) AS total_spend,
users.country AS country
FROM `bigquery-public-data.thelook_ecommerce.users` AS users
JOIN `bigquery-public-data.thelook_ecommerce.orders` AS orders
ON users.id = orders.user_id
JOIN `bigquery-public-data.thelook_ecommerce.order_items` AS order_items
ON orders.order_id = order_items.order_id
WHERE users.country = 'Japan'
GROUP BY users.id, users.first_name, users.last_name, users.email, users.country
ORDER BY total_spend DESC
LIMIT 10;
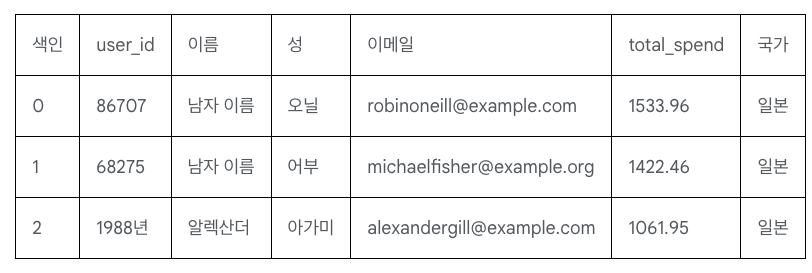
먼저 dry run 으로 시험해 보는 것이 좋습니다 .
import google.cloud.bigquery as bq
client = bq.Client(project="<your-project-id>")
client.query(result).result().to_dataframe()
이제 BigQuery 데이터를 LLM 솔루션에 통합하는 방법을 살펴보았습니다. 직접 사용해 보려면 Generative AI 샘플 리포지토리 에서 제공되는 노트북을 사용해 실험해 볼 수 있습니다 .