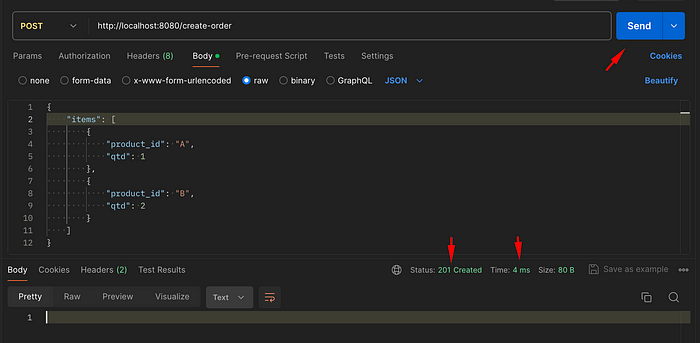
컨테이너화된 애플리케이션이 제공되는 클라우드 서비스 공급자(CSP)에서 현대적인 3계층 서버리스 애플리케이션을 생성하는 것은 많은 클라우드 엔지니어의 일반적인 작업입니다. 문제는 개발 노력을 가속화하고 비용과 복잡성을 줄이는 동시에 다양한 애플리케이션 계층에 대한 CSP의 광범위한 서비스를 효율적으로 활용할 수 있다는 것입니다. 이 문서에서는 배포 시간을 단축하는 동시에 비용과 복잡성을 줄이는 현대적인 3계층 서버리스 애플리케이션을 Google Cloud에 배포하기 위한 단계별 가이드와 이 구현에 사용되는 서비스에 대한 자세한 설명을 제공합니다.
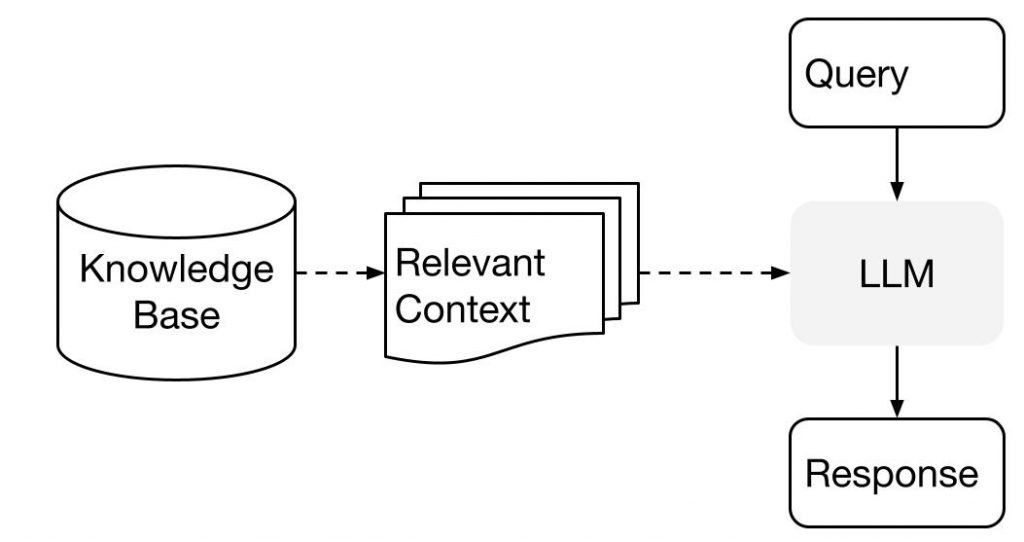
프런트엔드(프레젠테이션 계층), 백엔드(애플리케이션 계층), Firestore 데이터베이스(데이터 계층)로 구성된 3계층 마이크로서비스 아키텍처를 사용하는 "Amazing Employees"라는 예제 애플리케이션을 사용하겠습니다. Angular를 사용하여 개발된 프런트엔드는 사용자와 상호 작용하고, Python Flask로 구축된 백엔드는 비즈니스 로직을 관리합니다. “Amazing Employees”는 단일 프런트엔드 및 백엔드 컨테이너로 구성됩니다. 그러나 마이크로서비스 아키텍처는 확장 가능합니다. 더 많은 컨테이너를 추가하면 더 많은 기능을 활용할 수 있습니다. 애플리케이션의 인프라는 Terraform을 통해 정의되며 Cloud Build는 애플리케이션의 빌드 및 배포를 관리합니다.
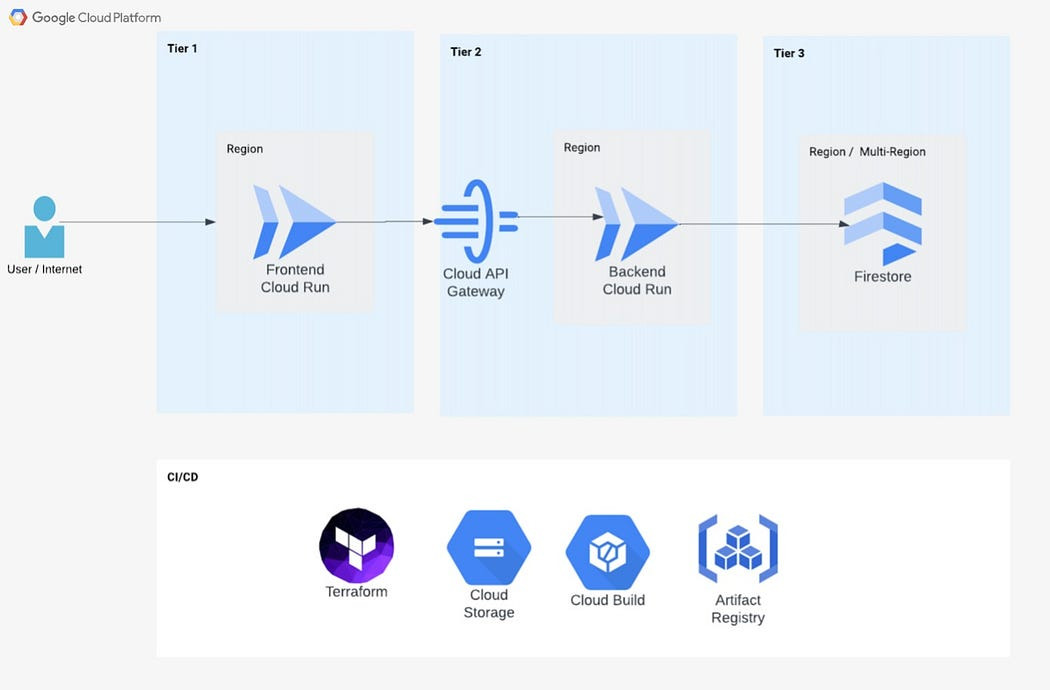
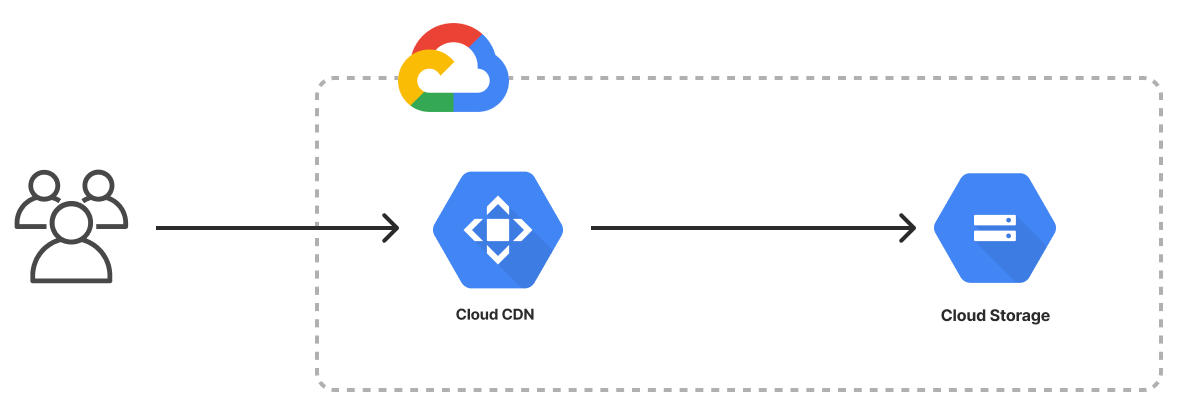
그림 1: Google Cloud 3계층 서버리스 아키텍처.
왜 서버리스인가?
서버리스 기술은 인프라 관리의 복잡한 작업 대부분을 CSP에 오프로드하여 개발자가 애플리케이션 코드 생성 및 배포에 집중할 수 있도록 합니다. 서버리스 제품은 다음을 포함하여 많은 이점을 제공합니다.
- 거의 무한한 자동 스케일링
- 고가용성
- 단순화된 인프라 관리
- 잠재적인 비용 절감(사용한 만큼만 비용 지불)
- 더 빠른 개발 주기
서버리스 기술은 마이크로서비스 아키텍처와 같이 확장성이 뛰어난 여러 아키텍처 유형을 지원하는 데 도움이 됩니다. 마이크로서비스는 애플리케이션을 독립적으로 배포할 수 있는 더 작은 단위로 나눕니다. 개별 마이크로서비스를 동적으로 확장하고 오류를 격리하는 기능을 통해 개발자는 응답성이 뛰어나고 비용 효율적인 솔루션을 만들 수 있습니다. 서버리스 기술은 마이크로서비스 애플리케이션을 생성하는 데 필요하지 않지만 관리 및 확장 측면을 크게 단순화하므로 리소스 활용도를 최적화하고 개발 노력을 간소화하려는 조직에 이상적인 선택입니다.
서버리스 애플리케이션의 또 다른 일반적인 아키텍처는 이벤트 중심 아키텍처입니다. 이 아키텍처에서는 애플리케이션이 사용자 작업, 데이터 변경, 외부 시스템 상호 작용 등 다양한 소스에 의해 트리거되는 이벤트에 동적으로 응답합니다. 이를 통해 개발자는 들어오는 이벤트에 따라 자동으로 확장되는 시스템을 설계하여 최대 부하 시 최적의 성능을 보장하고 조용한 기간 동안 비용 절감을 보장할 수 있습니다.
응용 서비스
'Amazing Employees' 애플리케이션의 프런트엔드와 백엔드를 위해 Google Cloud의 완전 관리형 서버리스 컨테이너 환경인 Cloud Run을 활용합니다. Cloud Run은 Google Cloud가 개척한 서버리스 컨테이너 기술인 Knative를 기반으로 합니다. Cloud Run은 인프라 계층을 추상화하고 기본 Kubernetes 클러스터를 관리할 필요가 없기 때문에 Google Kubernetes Engine(GKE)과 같은 다른 컨테이너 조정 서비스보다 사용하기 쉬운 경우가 많습니다. Cloud Run은 수신 트래픽을 기준으로 컨테이너를 자동으로 확장합니다. Google Cloud에서 서버리스 프런트엔드 또는 백엔드를 구축하는 데 널리 사용되는 또 다른 선택인 Cloud Functions의 최신 버전은 백그라운드에서 Cloud Run을 사용합니다.
물론 단순함을 통해 얻는 것은 통제력을 잃게 됩니다. 이는 클라우드의 모든 관리형 서비스에 해당됩니다. 사용 사례에서 컨테이너를 완전히 제어해야 하는 경우(세부적인 수준에서 네트워킹, 확장, 리소스 할당 구성 등) Cloud Run 대신 GKE를 사용해야 할 수도 있습니다. 가능하다면 Cloud Run과 같은 완전 관리형 서비스를 사용하는 것이 좋습니다. 간단히 말해 삶이 훨씬 편해지기 때문입니다.
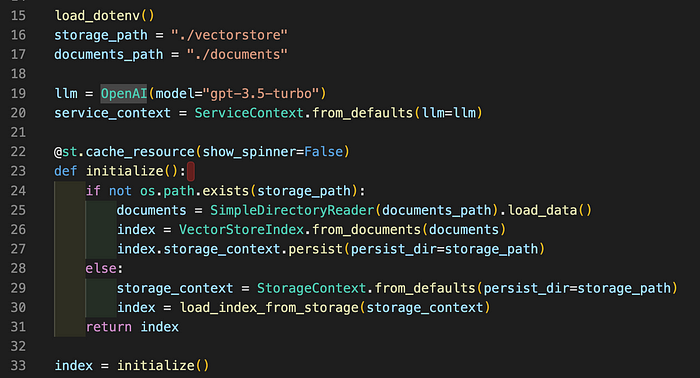
API 게이트웨이는 프런트엔드와 백엔드 Cloud Run 인스턴스 간의 트래픽을 보호하는 데 사용됩니다. 일반적으로 API 게이트웨이를 사용하는 것은 복잡성을 줄이면서 보안, 성능 및 유연성을 향상시키기 때문에 마이크로서비스 아키텍처를 구축할 때 모범 사례입니다. Google Cloud의 API 게이트웨이에는 API, 게이트웨이, 구성이라는 세 가지 주요 구성요소가 있습니다. 구성은 OpenAPI 사양을 사용하며 infra 디렉터리에서 볼 수 있습니다. 두 가지 변수가 사용되므로 수동으로 변경하지 않고도 구성을 배포할 수 있습니다. 첫 번째 변수는 Variable.tf 에 제공되는 ${project\_id} 이고 , 두 번째 변수는 ${url} 입니다 . ${url} 변수 값은 백엔드 Cloud Run 인스턴스의 URL을 확인하고 이를 구성에 추가하는 Terraform 데이터 블록에서 제공됩니다. 두 경우 모두 변수 대체는 Terraform을 통해 수행되며 infra/api-gateway.tf 에서 볼 수 있습니다 .
애플리케이션 데이터베이스의 경우 서버리스 아키텍처에 원활하게 통합되는 Firestore가 자연스러운 선택이었습니다. Google Cloud Firebase 서비스의 NoSQL 데이터베이스인 Firestore는 주로 자동 확장, 강력한 쿼리 지원, 고급 보안 규칙 및 신뢰할 수 있는 애플리케이션 인증을 제공하는 기능 때문에 선택되었습니다. 우리 애플리케이션의 맥락에서 우리는 사용자 로그인에 Firebase 인증을 사용하고 직원 데이터 관리를 위해 기본 CRUD 데이터베이스 작업을 사용합니다.
인프라 및 배포
코드형 인프라의 경우 HashiCorp가 개발한 오픈 소스 도구인 Terraform을 사용합니다. Terraform을 사용하면 Google Cloud를 포함한 다양한 클라우드 제공업체 전반에 걸쳐 선언적 방식으로 인프라 리소스를 정의, 관리, 프로비저닝할 수 있습니다.
선택적으로 Cloud Storage를 사용하여 Terraform 상태를 저장할 수 있습니다. Cloud Storage는 파일, 미디어 등 구조화되지 않은 데이터를 저장할 수 있고 여러 스토리지 클래스에 걸쳐 방대한 양의 데이터를 관리할 수 있는 확장성을 제공하는 Google Cloud 내의 객체 스토리지 서비스입니다. Cloud Storage는 복제를 통해 데이터 내구성을 제공하고 짧은 지연 시간으로 접근성을 제공합니다. 액세스 제어 및 암호화와 같은 보안 기능; 버전 관리, 수명 주기 관리, 다른 Google Cloud 서비스와의 통합 등이 있습니다.
애플리케이션의 프런트엔드와 백엔드를 구축하기 위해 Google Cloud에서 빌드를 실행할 수 있는 Google Cloud의 서버리스 CI(지속적 통합) 및 CD(지속적 배포) 플랫폼인 Cloud Build를 사용합니다.
컨테이너 이미지를 저장하기 위해 우리는 Java, Node, Python용 패키지와 같은 소프트웨어 아티팩트에 대한 안전하고 확장 가능한 저장소를 제공하는 Google Cloud의 관리형 서비스인 Artifact Registry를 활용하지만, 이 경우에는 Docker 이미지를 저장하는 데 이를 사용하겠습니다.
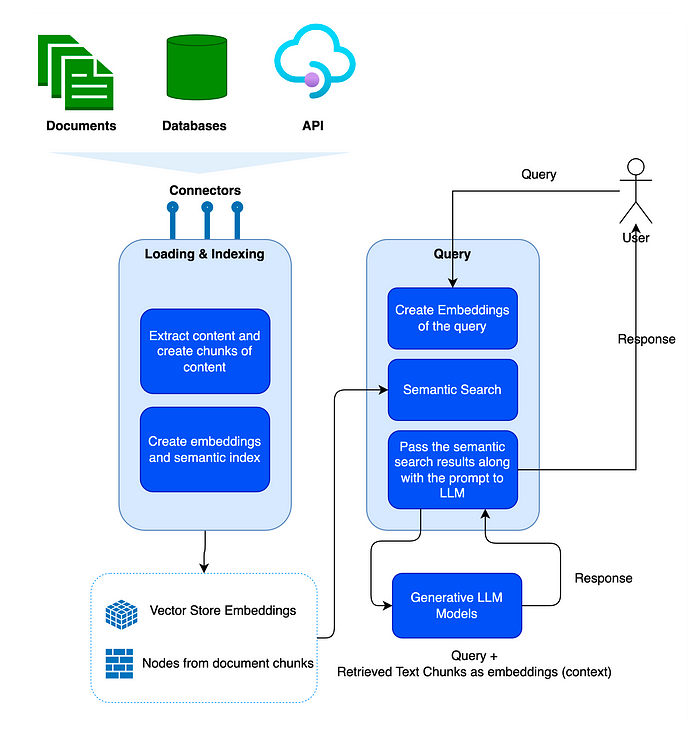
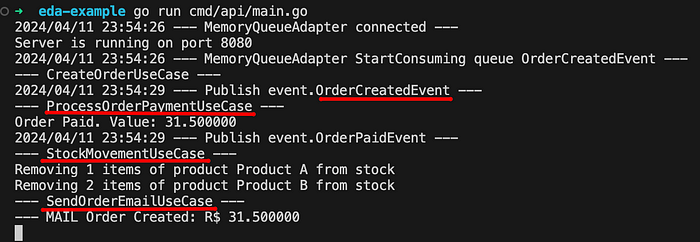
다음은 Cloud Build 작업의 흐름을 보여주는 단계 및 개략적인 다이어그램에 대한 설명입니다.
- 사용자가 Google Cloud 명령어를 사용하여 로컬 저장소에서 Cloud Build를 트리거합니다.
- Docker 이미지는 현재 작업 디렉터리에서 빌드됩니다.
- Docker 이미지가 Artifact Registry로 푸시됩니다.
- Cloud Run 인스턴스는 Docker 이미지에서 배포됩니다.
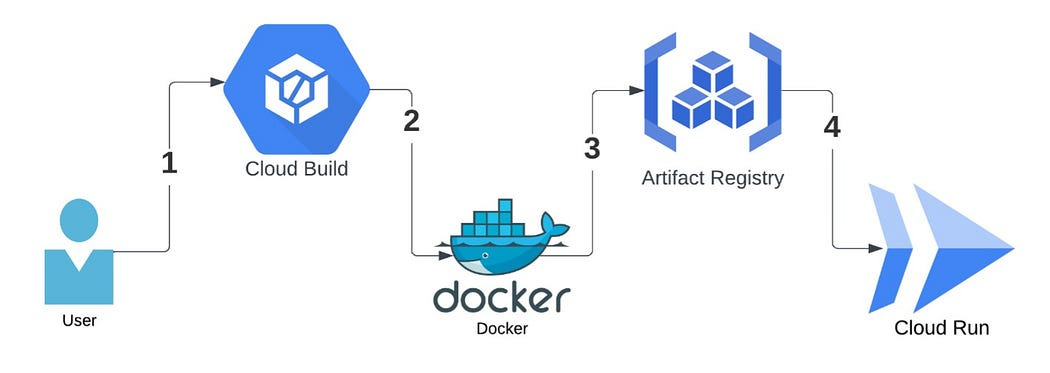
그림 2: Cloud Build 실행 흐름.
비용에 대한 참고 사항
이 문서는 Google Cloud의 서버리스 제품을 살펴보고 싶어하는 클라우드 엔지니어를 위해 작성되었습니다. 따라서 비상업적 사용을 위한 일반적인 애플리케이션 배포에는 Google Cloud 무료 프로그램이 적용되어야 합니다. 자세히 알아보려면 Google Cloud 무료 등급 제품 페이지 (https://cloud.google.com/free) 를 방문하세요 . 다음은 이 튜토리얼에 사용할 서비스 및 관련 비용(2023년 9월 기준)입니다.
- Cloud Run 무료 등급은 월간 요청 200만 개, 메모리 360,000GB-초, 컴퓨팅 시간 180,000vCPU-초, 네트워크 송신 1GB(북미만 해당)를 제공합니다.
- Firestore 무료 등급은 프로젝트당 1GB의 스토리지와 프로젝트당 일일 읽기 50,000회, 쓰기 20,000회, 삭제 20,000회를 제공합니다.
- API 게이트웨이는 무료 계층 서비스에 포함되지 않지만 청구 계정당 매월 최대 200만 개의 API 호출을 무료로 제공합니다.
- Cloud Build 무료 등급은 하루 120분의 빌드 시간을 제공합니다.
- Artifact Registry 무료 등급은 매월 0.5GB의 저장용량을 제공합니다.
여기서는 서버리스 3계층 웹 애플리케이션에 대한 비용 추정의 한 가지 예를 예시 번호와 함께 살펴보겠습니다. 실제 비용은 사용량에 따라 달라집니다.
비용 추정을 위해 다음 가정을 사용합니다.
- Cloud Run은 서비스로 사용되며 실행 시에만 CPU가 할당됩니다.
- Cloud Run 인스턴스에는 vCPU 1개와 메모리 512MB가 있습니다.
- 월간 사용자는 10,000명입니다.
- 각 사용자는 매월 평균 400건의 요청을 받습니다.
- 각 요청을 완료하는 데 1,000밀리초가 걸립니다.
- 요청의 60%는 데이터베이스 읽기입니다.
- 요청의 40%는 데이터베이스 쓰기입니다.
- Firestore의 데이터 용량은 15GB 미만입니다.
- 모든 리소스는 동일한 지역에 배포됩니다.
API 게이트웨이:
월간 요청 200만~10억 건 = 3.00 USD
Firestore:
15GB 스토리지 = 월 $2.52
Document reads:
50,000
문서 100,000개당 $0.036
Document writes:
20,000
문서 100,000개당 $0.108
사용자 100명 * 월별 요청 40,000개 = 월별 요청 400만 개 ⇒ 월별 읽기 240만 개 및 쓰기 160만 개
읽기 비용: 읽기 240만 개 / 일일 요청 30 ➡ 80,000개 — 무료 요청 50,000개 = 일일 유료 요청 30,000개 = 읽기 요청의 경우 하루 $0.036 * 30 = 월 $1.08
쓰기 비용: 쓰기 160만 개 / 일일 요청 30 ➡ 54,000개 — 무료 요청 20,000개 = 일일 유료 요청 34,000개 = 쓰기 요청의 경우 일일 0.216 USD * 30 = 월 6.48 USD
Egress:
동일한 지역 내 = $0.00
Cloud Run:
CPU 할당 시간: 200,000 vCPU-초 = $0.48
메모리 할당 시간: 100,000GiB-초 = $0.00
요청 수: 4,000,000 = $0.80
Cloud Run 총액: $1.28 * 인스턴스 2개 = 월 $2.56
Monthly costs:
API 게이트웨이: $3.00
소방서: $10.08
송신: $0.00
클라우드 런: $2.56
총액 = 월 $15.64
단계별 가이드
Google Cloud 프로젝트 설정
Google Cloud에서 리소스를 관리하고 구성하려면 프로젝트가 필요합니다. 이 튜토리얼에서는 새 프로젝트를 생성하는 것이 좋습니다. 이 가이드에서는 관리자(소유자) 액세스 권한이 있는 Google Cloud 프로젝트가 있고 nano 또는 vim과 같은 명령줄 편집기에 대한 지식이 있거나 Cloud Shell 편집기에 대한 액세스 권한이 있는 Google Cloud Shell에 액세스할 수 있다고 가정합니다. Cloud Shell 편집기는 Cloud Shell에 바로 내장된 텍스트 편집기이며 명령줄 편집기에 익숙하지 않은 경우 유용한 옵션입니다.
Google Cloud 콘솔에서 프로젝트에 액세스하려면 Google Cloud 콘솔 로 이동하여 로그인(또는 계정 생성)하고 프로젝트를 선택하세요. 아직 Google Cloud 프로젝트가 없다면 메뉴 > IAM 및 관리자 > 프로젝트 만들기 로 이동하여 콘솔의 메시지를 따릅니다.
초기 설정
단순화를 위해 단일 저장소를 사용하여 모든 애플리케이션, 인프라 및 파이프라인 코드를 보관합니다. 초기 설정을 위해 프로젝트의 Google Cloud 콘솔에서 Cloud Shell 세션을 엽니다. Cloud Shell은 개발 및 운영 작업을 위한 인터넷 기반 플랫폼을 나타내며 웹 브라우저를 통해 편리하게 접근할 수 있습니다. Google Cloud는 이 서비스를 무료로 제공합니다. 이 플랫폼 내에서 다양한 도구를 갖춘 온라인 터미널을 사용하여 자산을 감독할 수 있습니다. 사전 설치된 도구에 대해 자세히 알아보려면 https://cloud.google.com/shell/docs/how-cloud-shell-works#tools 를 참조하세요 .
https://console.cloud.google.com/?cloudshell=true를 방문하여 새 Cloud Shell 세션을 열 수 있습니다 .
아직 업데이트하지 않은 경우 Google Cloud Shell 콘솔을 업데이트하여 프로젝트를 사용하세요.
gcloud config set project [YOUR GOOGLE CLOUD PROJECT]
gcloud config list
1단계: GitHub 저장소 복제
Cloud Shell 세션에서 참조 애플리케이션을 git clone합니다. 이 저장소를 복제하여 시작할 수 있습니다. 그러나 리포지토리를 포크하고 포크된 리포지토리를 복제하는 것이 좋습니다. 이 단계별 가이드의 일부로 Google 프로젝트에 3계층 서버리스 애플리케이션을 배포하기 위해 코드를 변경하는 방법에 대한 지침을 제공합니다.
git clone [original https://github.com/maksoodmohiuddin/google-cloud-serverless-app-pattern.git or forked repo] cd google-cloud-serverless-app-pattern
여기에서 '편집기 열기'를 선택하여 Cloud Shell 편집기를 시작할 수 있습니다.
2단계: Google 프로젝트 ID 및 지역 업데이트
다음으로, 사용 중인 Google Cloud 프로젝트와 이 애플리케이션을 배포하려는 대상 Google Cloud 지역(예: 'us-west2')으로 project_id 및 위치를 업데이트하겠습니다 . 우리의 예에서는 nano를 편집기로 보여줍니다. 그러나 원하는 다른 사용 가능한 편집기를 사용하도록 선택할 수 있습니다.
cd infra
nano variables.tf
variable "project_id" {
description = "Project ID of the GCP project where resources will be deployed"
type = string
default = "PLEASE UPDATE WITH YOUR GOOGLE PROJECT ID"
}
variable "location" {
description = "Location (region) where resources will be deployed"
type = string
default = "PLEASE UPDATE YOUR GOOGLE CLOUD REGION"
}
Cloud Build, Cloud Run, Firebase, API Gateway, Artifact Registry를 지원하는 지역을 선택하세요. 개인 계정의 경우 Cloud Build는 특정 지역으로 제한됩니다. 따라서 개인 계정을 사용하는 경우 아래 지역 중 하나를 사용하는 것이 좋습니다.
Google Cloud 지역 및 이 앱 서비스가 지원되는 지역에 대해 자세히 알아보려면 다음을 방문하세요.
초기 인프라 배포
이 섹션에서는 Terraform을 사용하여 초기 인프라를 배포합니다. Terraform에 알려지지 않은 종속성 매핑으로 인해 특정 리소스를 대상으로 하고 애플리케이션을 순차적으로 설정해야 합니다. 기본적으로 Terraform은 terraform.tfstate
라는 파일에 상태를 로컬로 저장합니다 . 이 튜토리얼에서는 로컬 상태를 사용할 수 있습니다. 그러나 원하는 경우 Google Cloud Storage를 사용하여 상태를 원격 상태로 저장할 수 있습니다. 개발자가 여러 명인 프로젝트에서는 원격 상태가 항상 선호됩니다. Terraform에 특히 능숙하다면 Terraform 로컬 상태로 버킷을 만든 다음 해당 상태를 버킷으로 마이그레이션하는 것이 더 쉬울 수 있습니다. 자세한 내용은 Google Cloud 문서를 참조하세요.
1단계: Terraform 초기화
2단계: Terraform 계획 검증
Cloud Shell을 승인하라는 메시지가 표시되면 '수락'을 선택하여 계속하세요. 이는 Cloud Shell이 Google Cloud 명령어에 사용자 인증 정보를 사용하려면 권한이 필요하고 '승인'을 클릭하면 이 호출과 향후 호출에 대한 권한이 부여되기 때문입니다.
출력은 다음과 같아야 합니다.
계획: 추가 18개, 변경 0개, 파괴 0개
3단계: 초기 리소스에 Terraform 적용
메시지가 표시되면 "yes"를 입력하여 리소스를 배포합니다. 계획과 일치해야 합니다.
백엔드, API 게이트웨이, 프런트엔드 배포
1단계: Google 프로젝트를 사용하도록 백엔드 Python Flask 애플리케이션 코드 업데이트
백엔드 폴더로 이동하여 firestore.py 파일을 엽니다.
cd ../app/backend/ nano -l firestore.py
사용 중인 Google Cloud 프로젝트로 10행 클라이언트를 업데이트합니다.
client = firestore.Client(project="PLEASE_UPDATE_PROJECT_ID")
2단계: Cloud Build를 트리거하여 백엔드 배포
먼저 Cloud Build 파일을 검토하고 Google Cloud 명령줄을 사용하여 Cloud Build 파일을 기반으로 백엔드 Cloud Run을 배포할 수 있습니다.
cat backend-cloudbuild.yaml gcloud builds submit --region=[YOUR GOOGLE CLOUD REGION] --config backend-cloudbuild.yaml e.g. gcloud builds submit --region=us-west2 --config backend-cloudbuild.yaml
Cloud Build 실행을 완료하는 데 몇 분 정도 걸릴 수 있습니다. 이것은 예상됩니다. 이 Cloud Build 파일은 백엔드 서비스용 Docker 이미지를 빌드하여 Artifact Registry에 푸시한 후 Artifact Registry의 이미지를 Cloud Run 인스턴스에 배포합니다.
3단계: Swagger 사양 검토
OpenAPI Swagger 사양과 함께 API 게이트웨이를 사용하여 백엔드 Cloud Run을 API 게이트웨이에 연결하고 API 게이트웨이 구성을 설정합니다. infra 폴더 아래의 api-gateway--espv2-definition.yml.tmpl 파일을 검토합니다 .
먼저 cd를 사용하여 infra 디렉터리로 돌아가서 활성화 _api_gateway 플래그를 true로 활성화합니다.
cd ../../infra cat api-gateway--espv2-definition.yml.tmpl
다음을 방문하면 API Gateway 인증으로서 API Gateway, Swagger 및 Firebase용 OpenAPI 사양에 대해 자세히 알아볼 수 있습니다.
https://cloud.google.com/api-gateway/docs/openapi-overview
https://swagger.io
https://cloud.google.com/api-gateway/docs/authenticating-users-firebase
4단계: API 게이트웨이 배포
인프라 디렉터리에 있는 동안 활성화 _api_gateway 플래그를 true로 활성화합니다.
nano variables.tf
variable "enable_api_gateway" { description = "Feature flag to enable/disable API Gateway. Leverage this to deploy infra sequentially." type = bool default = true }
Terraform 계획을 실행한 후 적용합니다.
메시지가 표시되면 "yes"를 입력하여 리소스를 배포합니다. 세 가지 리소스를 배포해야 합니다. API 게이트웨이는 일반적으로 다른 리소스보다 배포하는 데 시간이 더 오래 걸립니다. 이것은 정상입니다.
5단계: Firebase 콘솔을 통해 Firestore 데이터베이스 구성
https://console.firebase.google.com/ 으로 이동하여 프로젝트 생성/추가 > 드롭다운에서 Google Cloud 프로젝트 선택 > 약관 동의 > 계속 > 계획 확인 > Google Analytics 활성화 여부 선택 > 계속을 선택합니다 .
Firebase 프로젝트의 방문 페이지에서 앱을 Firebase에 웹 앱으로 추가합니다.
또는 프로젝트 개요 에서 톱니바퀴 아이콘을 클릭하고 프로젝트 설정 으로 이동한 후 앱을 Firebase에 웹 앱으로 등록하세요.
선택한 이름으로 앱을 등록합니다(예: Google 프로젝트 이름을 사용할 수 있음).
앱이 등록되면 SDK 설정 및 구성 섹션(구성 섹션으로 전환 가능)에서 const firebaseConfig 값을 복사 하고 해당 값을 app/frontend/src/environments/environments.ts 에 붙여넣습니다 .
경고: Enviroment.ts 값 은 민감한 정보이므로 git 저장소에 체크인하지 마세요 .
cd ../app/frontend/src/environments/ nano -l environment.ts
export const environment = { firebase: { apiKey: "PLEASE UPDATE", authDomain: "PLEASE UPDATE", projectId: "PLEASE UPDATE", storageBucket: "PLEASE UPDATE", messagingSenderId: "PLEASE UPDATE", appId: "PLEASE UPDATE", measurementId: "PLEASE UPDATE" // if measurement is enabled }, production: false };
Firebase 콘솔에서 모든 제품 > 인증 > 시작하기 > Google > 활성화 > 지원 이메일 추가 > 저장 단계에 따라 Google을 Firebase용 인증 공급자로 활성화합니다.
6단계: 프런트엔드 API 게이트웨이 구성 설정
먼저 다음 명령을 실행하여 api-gateway 구성을 가져옵니다.
gcloud api-gateway gateways describe employee-gateway --location LOCATION --project PROJECT_ID --format 'value(defaultHostname)'
출력은 다음과 같습니다: Employee-gateway-#.#.gateway.dev
그런 다음 app/frontend/src/employee/services/firestore.service.ts 에서 세 개의 URL(13~15행)을 업데이트합니다 . 경로(예: 직원)를 그대로 유지합니다.
cd ../employee/services
nano -l firestore.service.ts
addEmployeeUrl = 'https://employee-gateway-#.#.gateway.dev/employee'; employeesUrl = 'https://employee-gateway-#.#.gateway.dev/employees'; deleteEmployeeUrl = 'https://employee-gateway-#.ue.gateway.dev/employee';
7단계: Cloud Build를 트리거하여 프런트엔드 배포
프런트엔드 폴더로 이동하여 Cloud Build 파일을 검토하고 Google Cloud CLI를 사용하여 백엔드 클라우드 인스턴스를 배포합니다.
cd ../../.. cat frontend-cloudbuild.yaml gcloud builds submit --region=[YOUR GOOGLE CLOUD REGION]] --config frontend-cloudbuild.yaml e.g. gcloud builds submit --region=us-west2 --config frontend-cloudbuild.yaml
8단계: 프런트엔드 Cloud Run URL로 Firebase 승인 도메인 업데이트
Firebase 앱에서 OAuth 작업을 수행하려면 프런트엔드 Cloud Run URL을 승인해야 합니다.
Google Cloud를 사용하여 Cloud Run URL을 가져올 수 있습니다.
gcloud run services describe SERVICE --region REGION --format 'value(status.url)'
e.g. gcloud run services describe amazing-employees-frontend-service --region us-west2 --format 'value(status.url)'
출력은 다음과 같아야 합니다. https://amazing-employees-frontend-service-###.a.run.app
해당 URL을 복사하고 Firebase 콘솔의 OAuth 리디렉션 도메인 목록에 추가하세요.
https://console.firebase.google.com/ 으로 이동하여 프로젝트를 선택합니다.
인증 > 설정 탭 > 승인된 도메인 > 도메인 추가를 클릭 하고 프런트엔드 Cloud Run URL을 붙여넣습니다.
마지막 단계: 엔드투엔드 앱 검증
프런트엔드 Cloud Run URL(https://amazing-employees-frontend-service-###.a.run.app)로 이동하고 Google 계정을 사용하여 앱에 로그인합니다. Google Cloud 서버리스 애플리케이션 패턴은 다음을 사용합니다. Cloud Run, API 게이트웨이, Firebase가 실행 중입니다.
정리하다
API 게이트웨이 구성 종속성으로 인해 여기서는 Terraform 삭제를 실행할 수 없습니다.
이 튜토리얼에서 사용한 리소스 비용이 GCP 계정에 청구되지 않도록 하려면 프로젝트를 삭제하면 됩니다.
프로젝트를 삭제하면 다음과 같은 결과가 발생합니다.
- 기존 프로젝트를 사용한 경우 해당 프로젝트에서 수행한 다른 작업도 모두 삭제됩니다.
- 삭제된 프로젝트의 프로젝트 ID는 재사용할 수 없습니다. 나중에 사용하려는 맞춤 프로젝트 ID를 만든 경우 대신 프로젝트 내의 리소스를 삭제하세요. 이렇게 하면 appspot.com URL과 같이 프로젝트 ID를 사용하는 URL을 계속 사용할 수 있습니다.
프로젝트를 삭제하려면 다음을 수행하세요.
요약
이 문서에서는 Google Cloud에 서버리스 3계층 애플리케이션을 배포하는 방법을 살펴보았습니다. 우리는 데이터베이스 요구사항에 Firestore를 활용하면서 Angular 컨테이너화된 프런트엔드와 Python Flask 컨테이너화된 백엔드 모두에 Cloud Run을 사용하는 방법을 살펴보았습니다. 효율적인 인프라 설정 및 배포를 위해 Terraform과 Cloud Build가 강조되었습니다. 실습을 원하는 분들을 위해 배포의 각 단계를 복제하고 이해할 수 있도록 자세한 단계별 가이드를 제공했습니다.
이러한 주요 구성요소와 기술을 이해함으로써 독자는 Google Cloud에서 서버리스 프로젝트를 처리할 수 있는 더 나은 준비를 갖추게 될 것입니다.