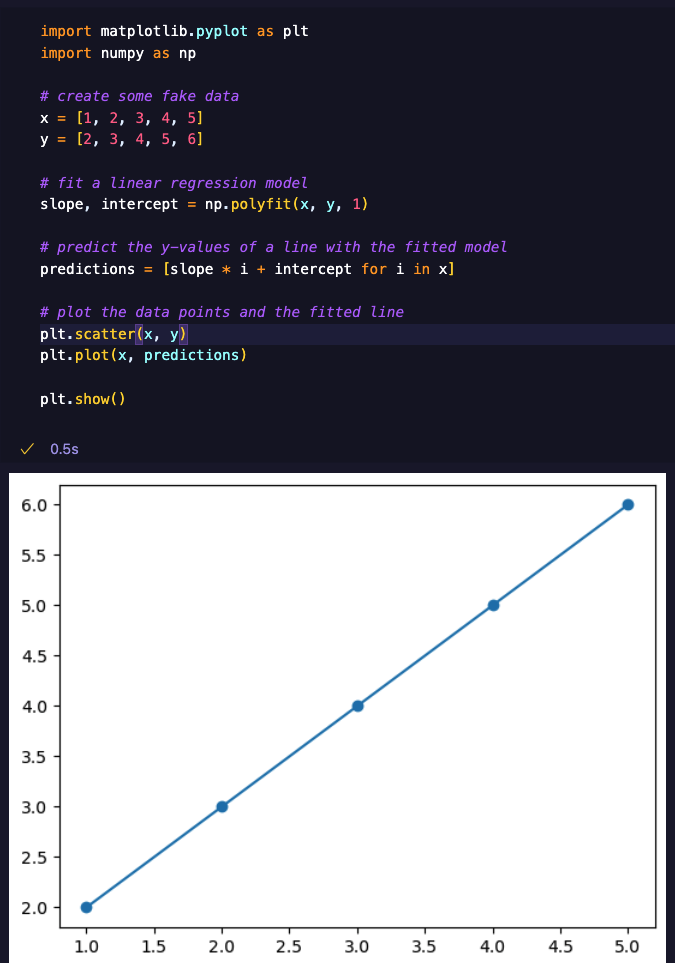
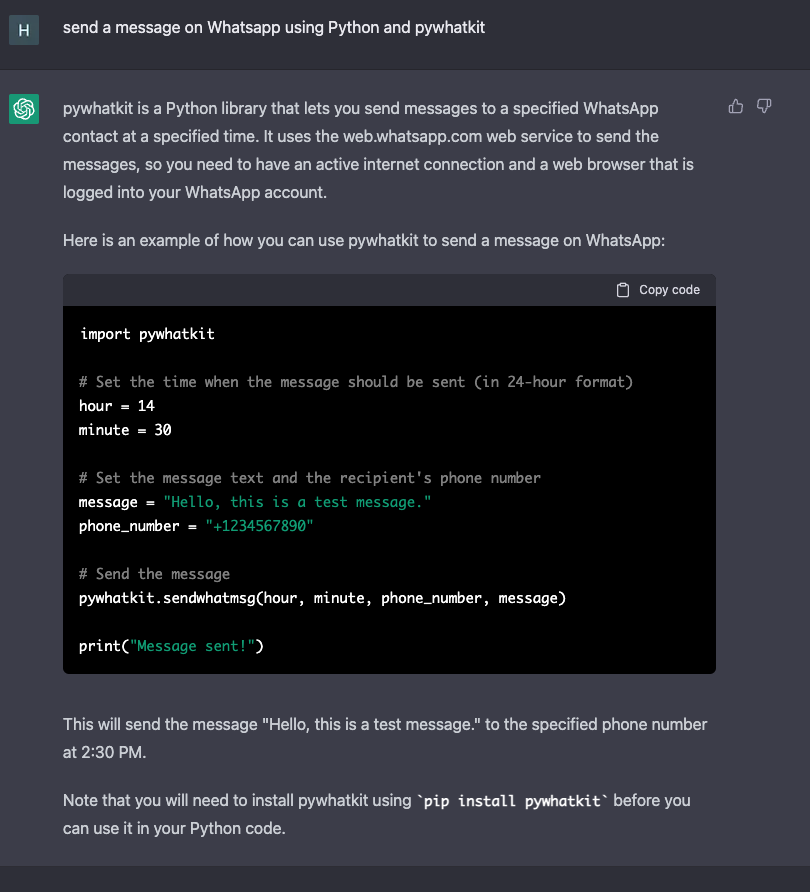
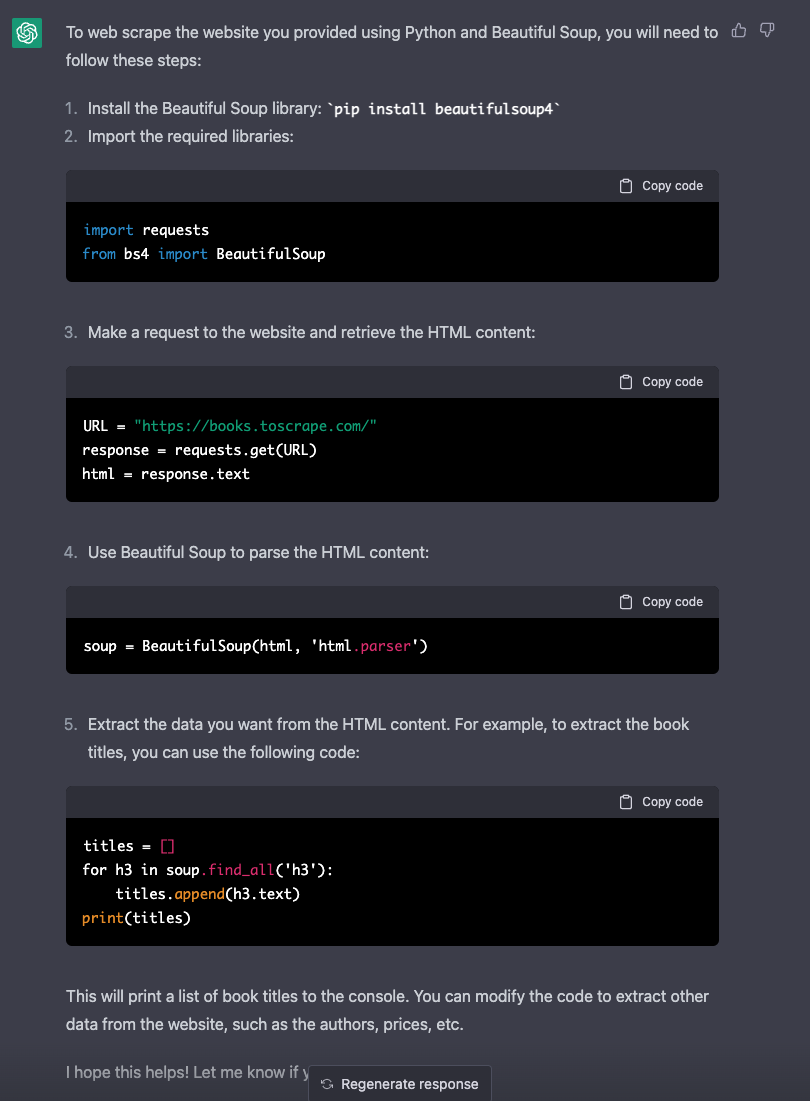
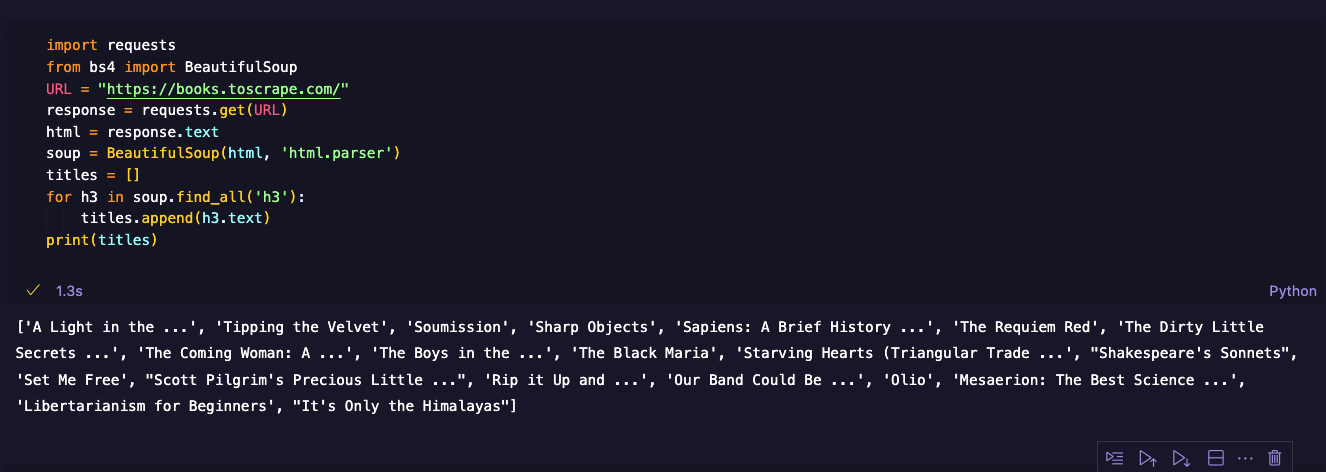
 Chatting with AI chatbots has never been more engaging and natural than with GPT-4. GPT-4, or Generative Pre-trained Transformer 4, is the latest AI model developed by OpenAI, a leading research organization in the field of artificial intelligence.
Chatting with AI chatbots has never been more engaging and natural than with GPT-4. GPT-4, or Generative Pre-trained Transformer 4, is the latest AI model developed by OpenAI, a leading research organization in the field of artificial intelligence.
What is GPT-4?
GPT-4 is an AI model that uses deep learning algorithms to generate human-like text. It is a language model that has been trained on a massive amount of data from the internet, including books, articles, and websites. The model is pre-trained on a diverse set of tasks, such as language translation, question-answering, and text summarization.
How was GPT-4 made?
 GPT-4 is the result of years of research and development by OpenAI. The model is based on the Transformer architecture, which was first introduced in the paper "Attention Is All You Need" by Google researchers in 2017. The Transformer architecture is a neural network that uses self-attention mechanisms to process input data.
GPT-4 is the result of years of research and development by OpenAI. The model is based on the Transformer architecture, which was first introduced in the paper "Attention Is All You Need" by Google researchers in 2017. The Transformer architecture is a neural network that uses self-attention mechanisms to process input data.
To train GPT-4, OpenAI used a massive amount of data from the internet, including books, articles, and websites. The model was trained using unsupervised learning, which means that it learned from the data without any human intervention. The training process took several months and required a massive amount of computational resources.
How does GPT-4 compare to previous AI chatbot models?
GPT-4 is the latest in a series of language models developed by OpenAI, following the success of GPT-3 and other models such as BERT. While these models share some similarities, there are also significant differences between them.
Compared to its predecessor, GPT-3, which was released in 2020 and quickly became known for its impressive language generation capabilities, GPT-4 promises even more advanced natural language processing abilities. With a larger training dataset and improved architecture, it is expected to generate more coherent and contextually appropriate responses than any AI chatbot before it.
BERT (Bidirectional Encoder Representations from Transformers), on the other hand, is a model developed by Google that excels at natural language understanding tasks like question answering and text classification. While it may not have the same level of language generation capabilities as GPT-4 or GPT-3, BERT's ability to understand complex contextual relationships makes it an important tool for many AI applications.
Overall, while each model has unique strengths and weaknesses, GPT-4 represents a major leap forward in AI chatbot technology with the potential to significantly improve our interactions with machines.
Characteristics of GPT-4
GPT-4 is known for its ability to generate human-like text that is engaging and natural. The model can understand the context of the conversation and generate responses that are relevant and coherent. It can also generate text in multiple languages and styles, including formal and informal language.
GPT-4 is also capable of learning from new data and adapting to new tasks. This means that it can be fine-tuned for specific applications, such as customer service or personal assistants.
Prospects for Future Use
GPT-4 has the potential to revolutionize the way we interact with chatbots and virtual assistants. The model can be used in a wide range of applications, such as customer service, healthcare, and education.
In customer service, GPT-4 can provide personalized and engaging responses to customers, improving customer satisfaction and loyalty. In healthcare, the model can be used to generate patient reports and assist doctors in diagnosing diseases. In education, GPT-4 can be used to generate personalized learning materials and provide feedback to students.
Impact of GPT-4 on the Job Market
 As with any technological advancement, there are concerns about the impact that GPT-4 will have on the job market. In particular, some experts predict that the model may replace human workers in certain roles, such as customer service representatives.
As with any technological advancement, there are concerns about the impact that GPT-4 will have on the job market. In particular, some experts predict that the model may replace human workers in certain roles, such as customer service representatives.
GPT-4's ability to generate personalized and engaging responses could make it an attractive alternative to human customer service representatives. Companies may choose to implement the model as a cost-saving measure, reducing their reliance on human workers.
However, it is important to note that GPT-4 is not designed to replace human workers entirely. The model is still limited by its programming and training data and may not be able to handle complex or emotional situations as well as a human representative.
Furthermore, GPT-4's potential for improving customer satisfaction and loyalty means that it could create new job opportunities in other areas. For example, companies may need more skilled workers to manage and fine-tune the model for specific applications.
Overall, while there may be some disruption in the job market due to GPT-4's capabilities, it is unlikely that it will completely replace human workers in customer service and other similar roles. Instead, we can expect a shift towards more specialized and skilled roles in managing AI models like GPT-4.
Use Cases for GPT-4 in Industries Beyond Customer Service, Healthcare and Education
While the use cases for GPT-4 in customer service, healthcare and education are well established, the potential applications of this technology extend far beyond these areas. In fact, there are already a number of exciting use cases being explored in industries such as finance and marketing.
One area where GPT-4 could have a significant impact is finance. The model's ability to analyze large amounts of data and generate insights could be invaluable for financial institutions looking to improve their decision-making processes. For example, GPT-4 could be used to analyze market trends and predict future stock prices with greater accuracy than traditional methods.
In marketing, GPT-4 could be used to create more personalized and engaging content for consumers. The model's ability to generate natural language text that is tailored to individual preferences and interests could help companies stand out in a crowded marketplace. Additionally, GPT-4 could be used to analyze consumer data and provide insights into buying behavior, allowing companies to optimize their marketing strategies.
Overall, the potential applications of GPT-4 extend far beyond the industries mentioned in this document. As more organizations begin to explore the capabilities of this technology, we can expect to see new and innovative use cases emerge across a wide range of industries.
People's Reactions and Actual Usage
GPT-4 has generated a lot of excitement and interest in the AI community. Many experts believe that the model represents a significant breakthrough in natural language processing and AI.
However, there are also concerns about the potential misuse of the technology, such as the generation of fake news or the manipulation of public opinion.
Despite these concerns, GPT-4 has already been used in several applications, such as chatbots and virtual assistants. The model has been praised for its ability to generate engaging and natural conversations, and it is expected to become even more prevalent in the future.
In conclusion, GPT-4 represents a significant breakthrough in the field of AI chatbots. The model's ability to generate human-like text and adapt to new tasks has the potential to revolutionize the way we interact with chatbots and virtual assistants. While there are concerns about the potential misuse of the technology, the prospects for future use are promising.
The future development of language models beyond GPT-4
 While GPT-4 represents a significant leap forward in AI chatbot technology, research is already underway to develop even more advanced language models. One area of focus for researchers is improving the ability of language models to understand and generate contextually appropriate responses.
While GPT-4 represents a significant leap forward in AI chatbot technology, research is already underway to develop even more advanced language models. One area of focus for researchers is improving the ability of language models to understand and generate contextually appropriate responses.
One approach that shows promise is the use of multimodal inputs, such as images and videos, to provide additional context for language models. By incorporating visual information into their understanding of language, these models could generate even more engaging and natural conversations.
Another area of focus is improving the ethical considerations surrounding the development and use of language models. As these models become more advanced and prevalent, it will be important to ensure that they are being used in ways that benefit society as a whole.
Finally, researchers are also exploring the potential for developing more specialized language models for specific industries or applications. For example, a language model designed specifically for medical applications could help doctors diagnose diseases or generate patient reports with greater accuracy than a general-purpose model like GPT-4.
Overall, while GPT-4 represents a major breakthrough in AI chatbot technology, there is still much room for further development and innovation in this field. As researchers continue to explore new approaches and techniques, we can expect to see even more advanced and sophisticated language models emerge in the years ahead.
Conclusion
All of the above articles were also written using the gpt language model. In this way, the era has arrived in whichcomputers create everything that has been created by humans, such as music, texts, videos, pictures, and coding. It seems that the era of making works with sincerity has almost passed. That role will now be replaced by computers, and how to use it in detail seems to be the focus.




 One of the biggest strengths of Memphis is its ease of use. It comes with a simple and intuitive API that makes it easy to get started with. It also has an excellent documentation that makes it easy to learn and troubleshoot. Memphis is highly reliable and can deliver messages with low latency, making it ideal for use cases that require real-time data processing.
One of the biggest strengths of Memphis is its ease of use. It comes with a simple and intuitive API that makes it easy to get started with. It also has an excellent documentation that makes it easy to learn and troubleshoot. Memphis is highly reliable and can deliver messages with low latency, making it ideal for use cases that require real-time data processing.
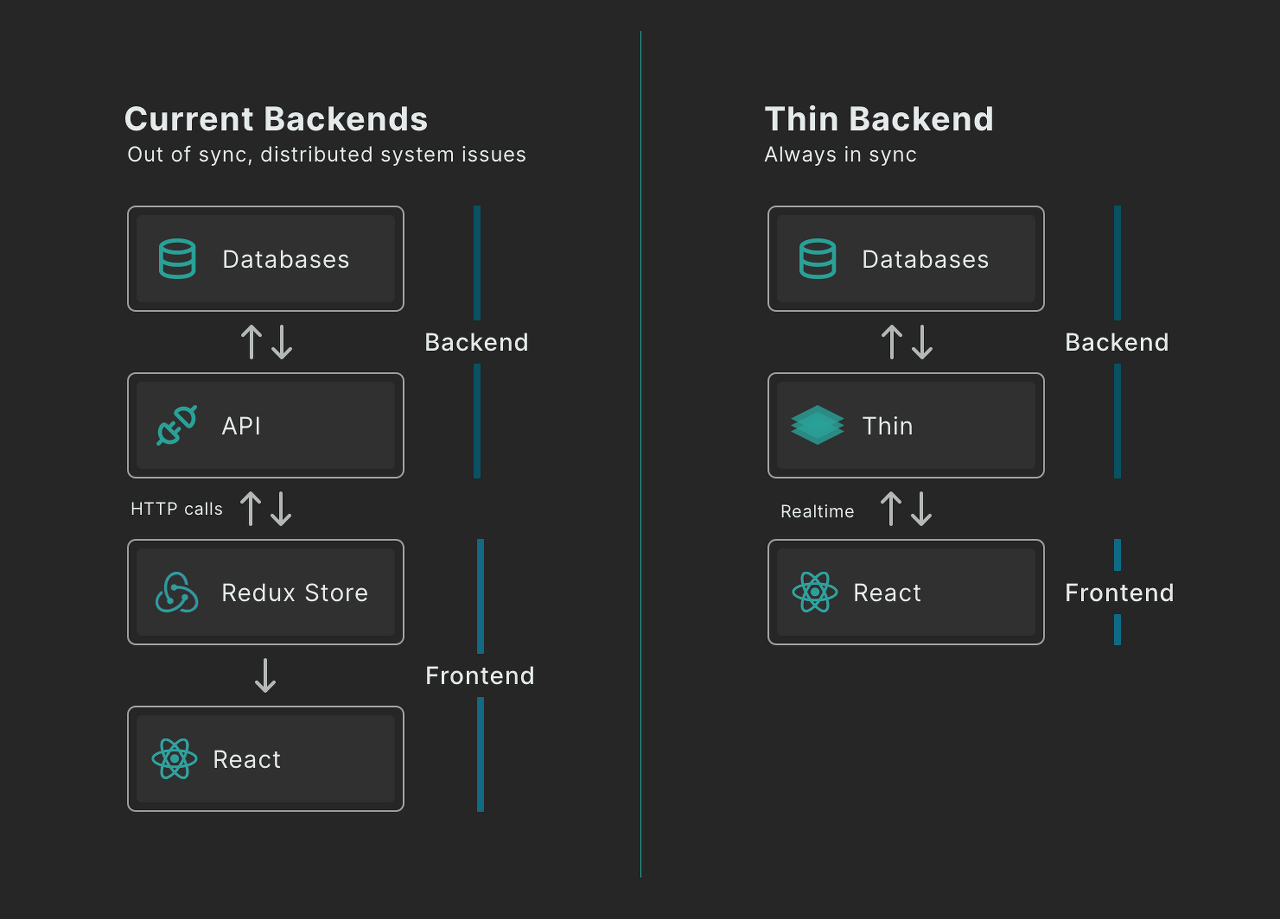

 One of the main limitations is that it may not be suitable for larger, more complex websites. Thin Backend is designed to be lightweight and efficient, which can make it an excellent choice for small to medium-sized websites. However, larger websites may require more complex functionality and may benefit from a traditional backend with a database.
One of the main limitations is that it may not be suitable for larger, more complex websites. Thin Backend is designed to be lightweight and efficient, which can make it an excellent choice for small to medium-sized websites. However, larger websites may require more complex functionality and may benefit from a traditional backend with a database. Are you tired of slow and inefficient data storage solutions? Look no further than Dragonfly, the in-memory data store that is taking the tech world by storm. With lightning-fast speed and compatibility with existing Redis and Memcached APIs, Dragonfly is the perfect solution for anyone looking to improve their data storage capabilities.
Are you tired of slow and inefficient data storage solutions? Look no further than Dragonfly, the in-memory data store that is taking the tech world by storm. With lightning-fast speed and compatibility with existing Redis and Memcached APIs, Dragonfly is the perfect solution for anyone looking to improve their data storage capabilities.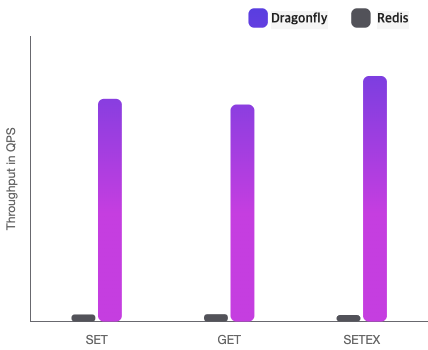 So how does Dragonfly stack up against other popular data storage solutions like Redis and Memcached? In terms of speed and performance, Dragonfly is the clear winner. Its in-memory architecture allows for lightning-fast data access and retrieval, while Redis and Memcached rely on disk-based storage that can slow things down.
So how does Dragonfly stack up against other popular data storage solutions like Redis and Memcached? In terms of speed and performance, Dragonfly is the clear winner. Its in-memory architecture allows for lightning-fast data access and retrieval, while Redis and Memcached rely on disk-based storage that can slow things down.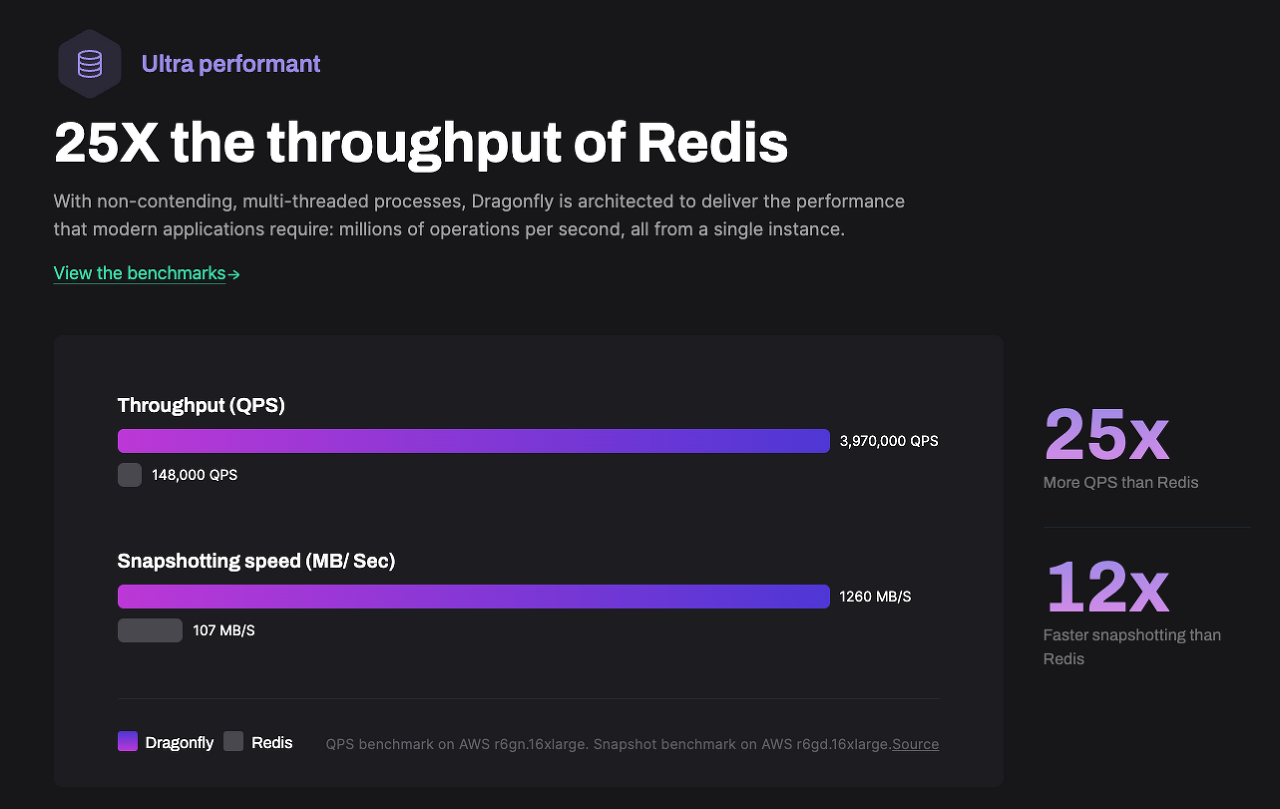 While Dragonfly's speed and performance are impressive, it can be more complex to set up and configure than Redis and Memcached. However, with a little bit of effort, you can ensure that your Dragonfly instance is optimized for maximum efficiency.
While Dragonfly's speed and performance are impressive, it can be more complex to set up and configure than Redis and Memcached. However, with a little bit of effort, you can ensure that your Dragonfly instance is optimized for maximum efficiency.